

前言
前边两篇文章分别写了FastGPT在windows系统中基础环境的搭建,以及FastGPT本体的部署,那么本篇文章就来写FastGPT如何接入大模型,包括在线大模型和本地大模型
在线大模型指的是各个云厂商提供的API,效果更好、速度更快、体验更好
本地大模型指的是在内网部署的,依赖本机显卡的大模型,一般来说AI回复效果稍差一些,主要取决于显卡的型号、数量。
在这里的教程中我先接入在线大模型,然后再开始本地模型的部署
前置教程文章
模型介绍(个人观点)
目前可以按照地域分成两类大模型:
一类是国内的,能够直接注册账号充值使用
一类是国外的,需要一些魔法才能注册账号,且还需要一些国外的信用卡、纯净的IP之类的,容易封号。
按照类型来分的话,可分5种:
语言模型:就平常用AI聊天的大模型
索引模型:给知识库用的模型
语音合成:将文本文字转为语音
语音识别:将语音转为文本文字
重排模型:给知识库用的,能提升回答精度的样子
对于FastGPT来说,并不需要太牛逼的模型,一般来说越快、越准确的大模型越好,毕竟工作流中可能有超多节点,每个节点都慢一点的话,整体来看就巨慢。同样的,我们希望大模型处理知识库的内容,也不希望模型有太高的幻觉(凭空捏造)
国内模型用的比较多的厂家就是:深度求索、智谱清言、通意千问、豆包这些
国外模型用的比较多的厂家就是:OpenAI、Claude、Google、X.ai
模型接入介绍
AI Proxy介绍
这个是和FastGPT同一个公司开发的,能够将市面上绝大多数的非OpenAI及OpenAI协议的类型转为OpenAI协议,以便接入各大三方平台,类似于OneAPI、NewAPI之类的
我记得前段时间AI Proxy还是一个独立的网站,今天部署之后发现它好像是和FastGPT集成了,能够直接在FastGPT的网站里添加各类国内外的大模型渠道
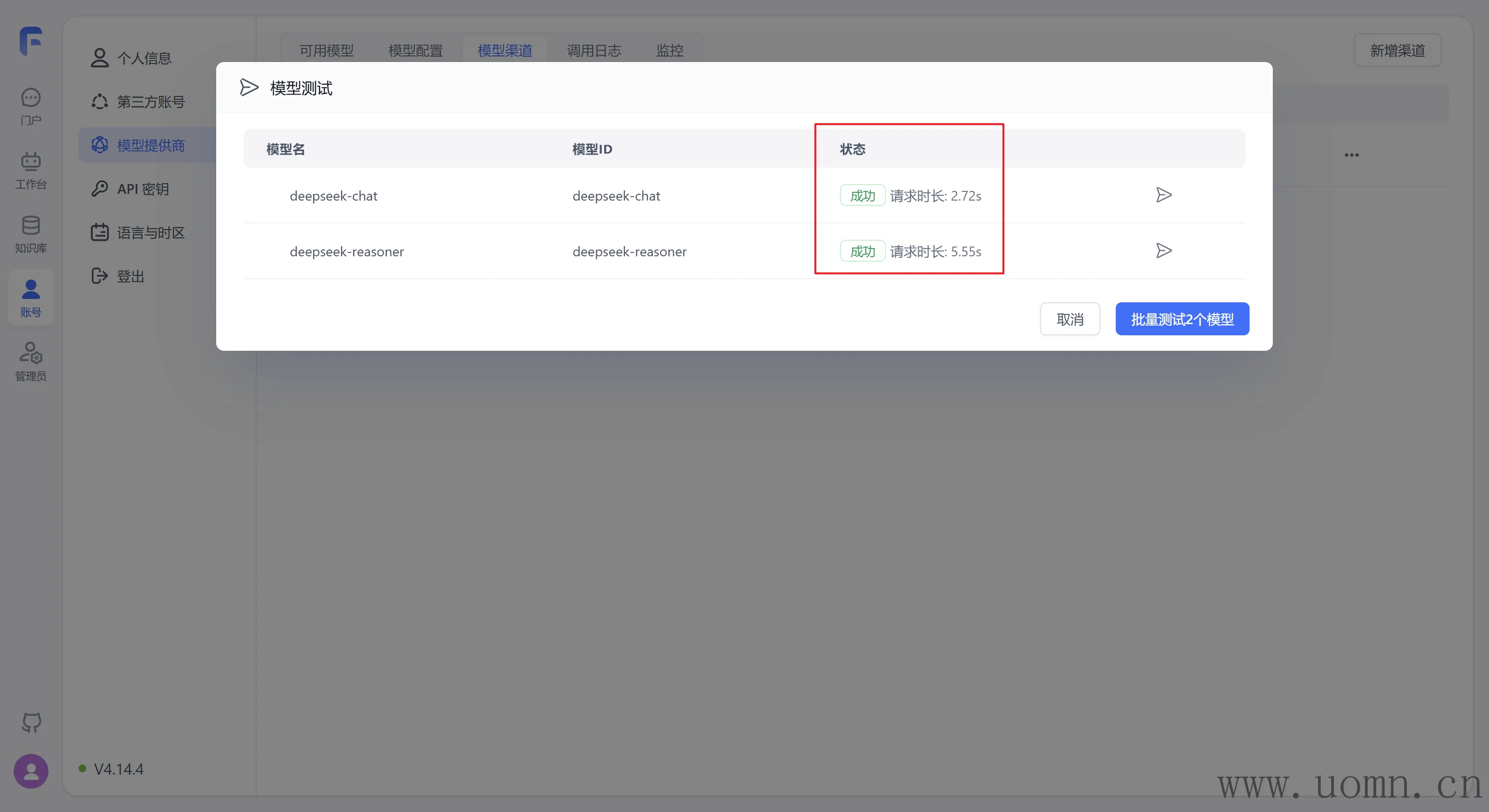
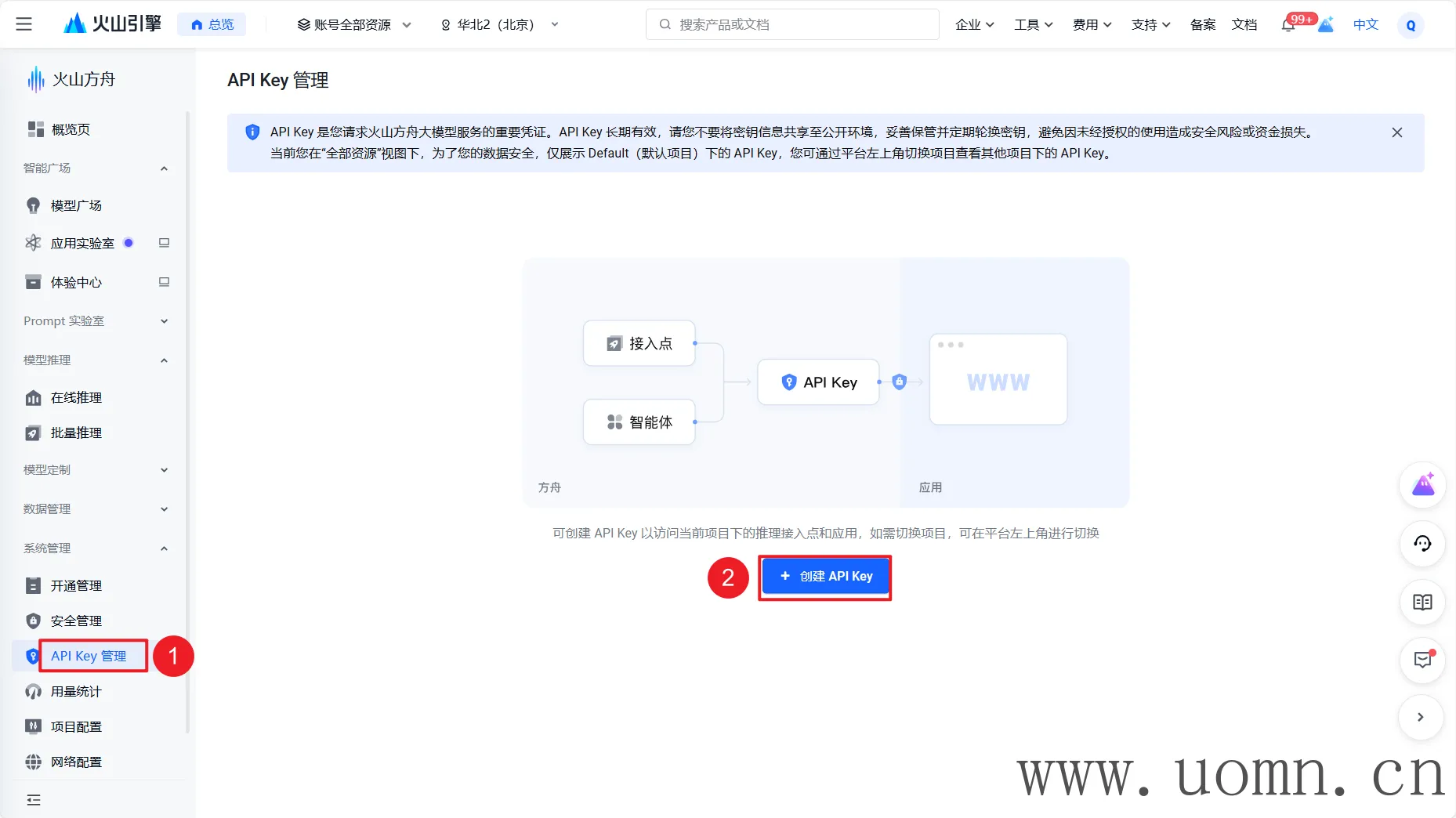
如何接入大模型
如下图
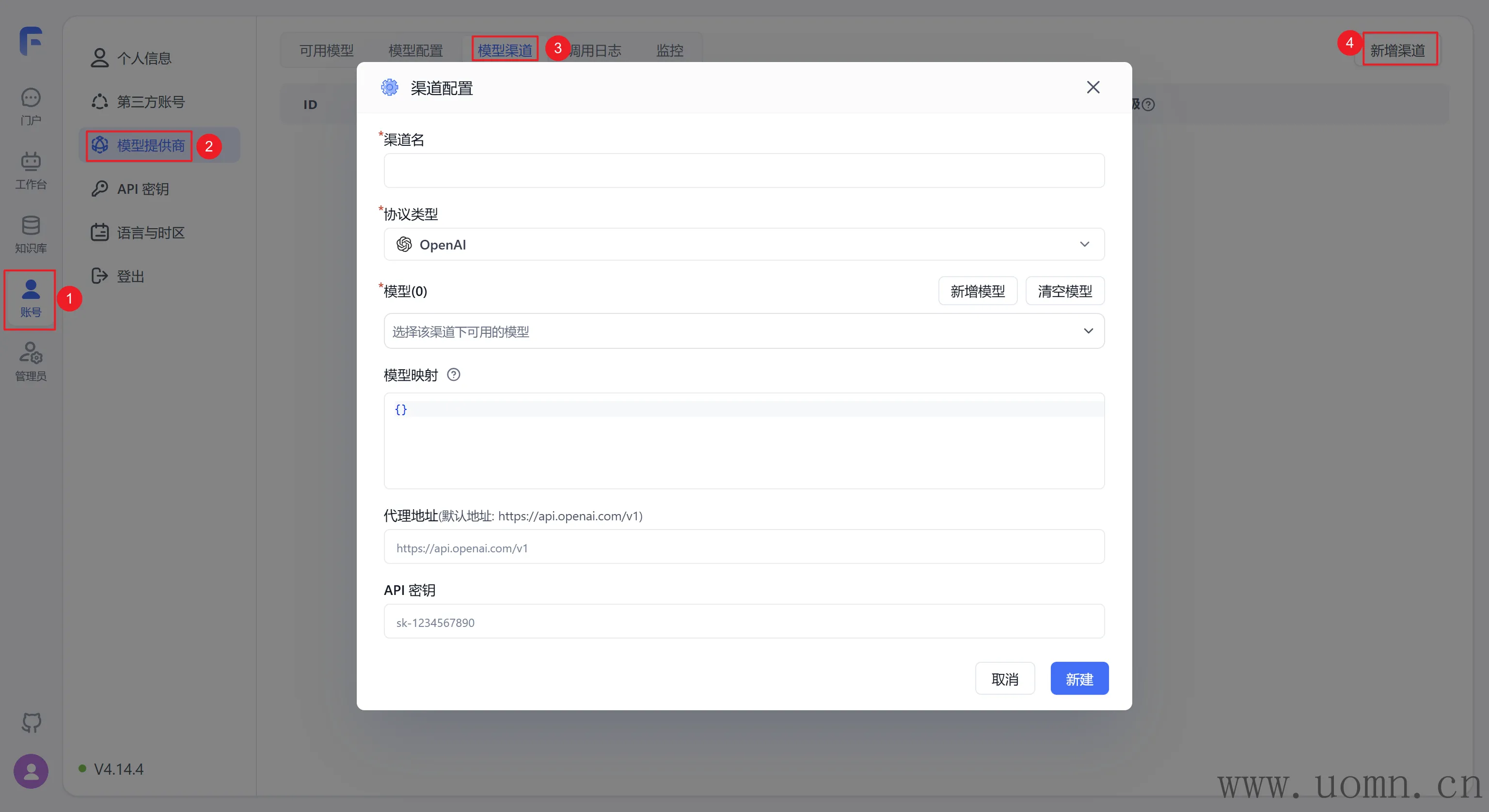
配置说明
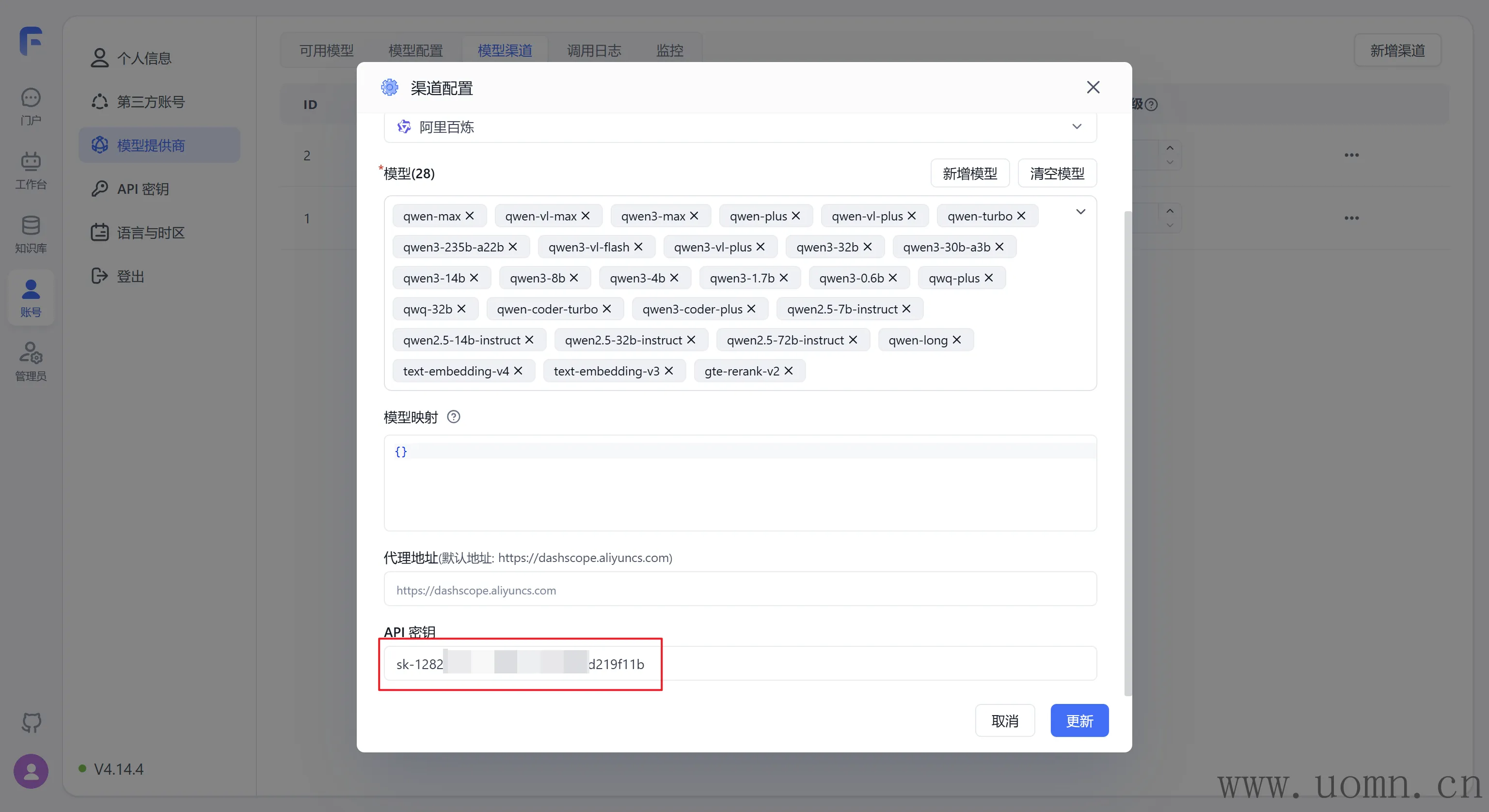
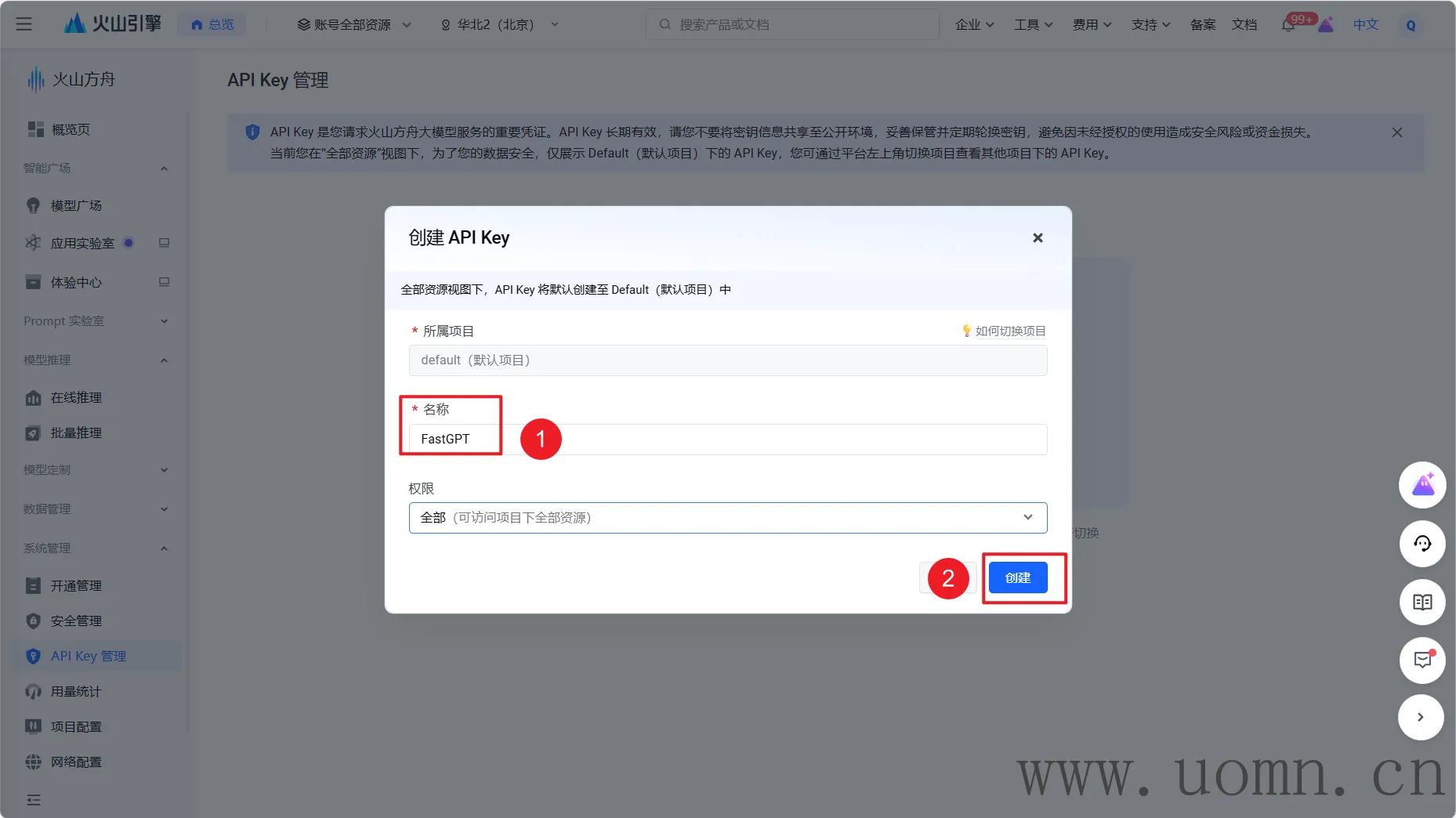
渠道名:随便写,用于区分的
协议类型:可以选择具体的大模型服务商,选择后,默认的代理地址会自动调整,可以不用去翻官方文档找API
模型:选择协议类型后,对应厂家的模型会置顶显示,方便选择。在选择模型的时候一定要选择对应服务商渠道的模型,选错了用不了哈
模型映射:非必要不用动,一般来说,后期工作流多了、AI节点多了的时候,想要更新模型就得挨个工作流进去重新选择新模型。那么此时我们可以在这里设置模型映射,来避免这些麻烦又重复的步骤。比如:我想将所有工作流中的gpt-4o-mini模型升级为gpt-5,那么就可以像下边这样设置。这样虽然在工作流中依旧使用的是gpt-4o-mini,但是实际请求到API的模型就变成了gpt-5
{
"gpt-4o-mini": "gpt-5"
}代理地址:请求的API地址,一般不用填写,选择协议类型的时候会自动填充对应的API
API密钥:需要去对应服务商的官网获取
特殊说明
在模型那里有个新增模型的按钮,一般使用情况如下:
大模型服务商更新了新的大模型,但是FastGPT还没把模型名同步过来
使用了中转API,这种API基本涵括了绝大多数市面上的模型,同时模型的名称也多种多样,有概率FastGPT这边没有
中转API的说明
中转API是一类模型服务商的统称,一般由个人或小团队运营,兼容OpenAI的协议类型
优点
模型价格相较于官方便宜
便于网站接入,基本99%的AI网站都是兼容OpenAI协议类型的
模型众多,不必在各个官方服务商处注册账号、充值、获取密钥,在中转API一处充值即可使用各个服务商的模型
缺点(大多数中转API服务商)
由于市面上很多开源的中转API的程序,比如AIProxy、NewAPI、OneAPI。部署也不难,所以网上中转API服务商属于是遍地开花了,质量参差不齐
模型掺假:例如我想用Claude(更贵、效果更好),结果服务商那里给你换成了gpt-4o-mini(更便宜、效果差一些)
模型限速:小服务商,号池比较少,人一多并发就不够用了
跑路:一旦某次大规模封禁账号,超出了预算,即刻关站跑路,找都找不到人,钱也不会退的
不开票:个人肯定没法开票,也就没法找公司报销喽
各模型服务商密钥获取
这里只放一些常用的国内大模型的密钥获取教程,然后网站的注册登录流程、充值流程我这里就不再写了
初始建议充值金额:10元
个人用,10块钱用很久了能够
DeepSeek
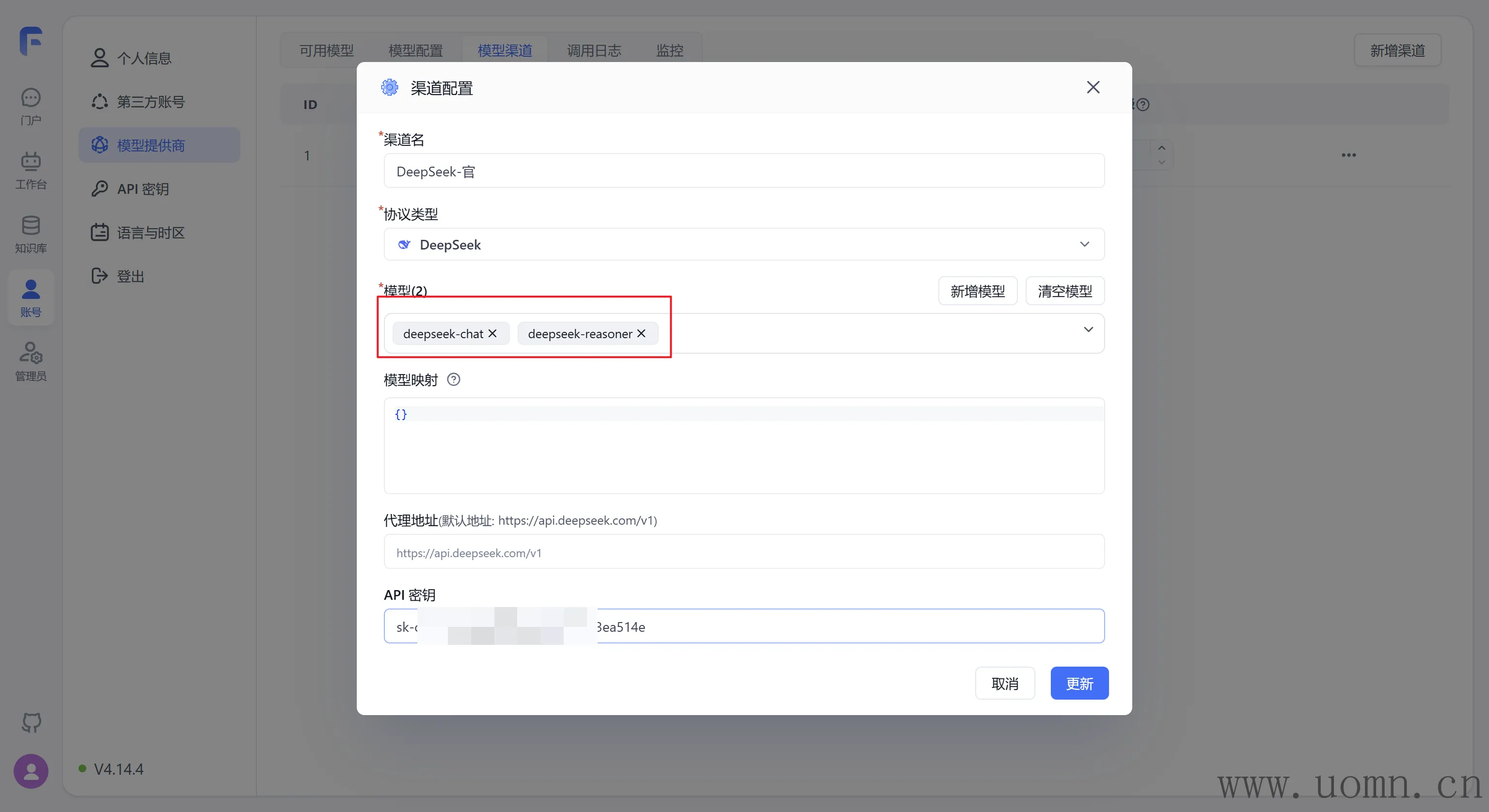
模型选择说明:对于官方渠道来说,只需要选择deepseek-chat deepseek-reasoner 两个,会自动指向最新模型版本,前一个是非思考模型,后一个是思考模型,目前最新版本为DeepSeek-V3.2
阿里百炼
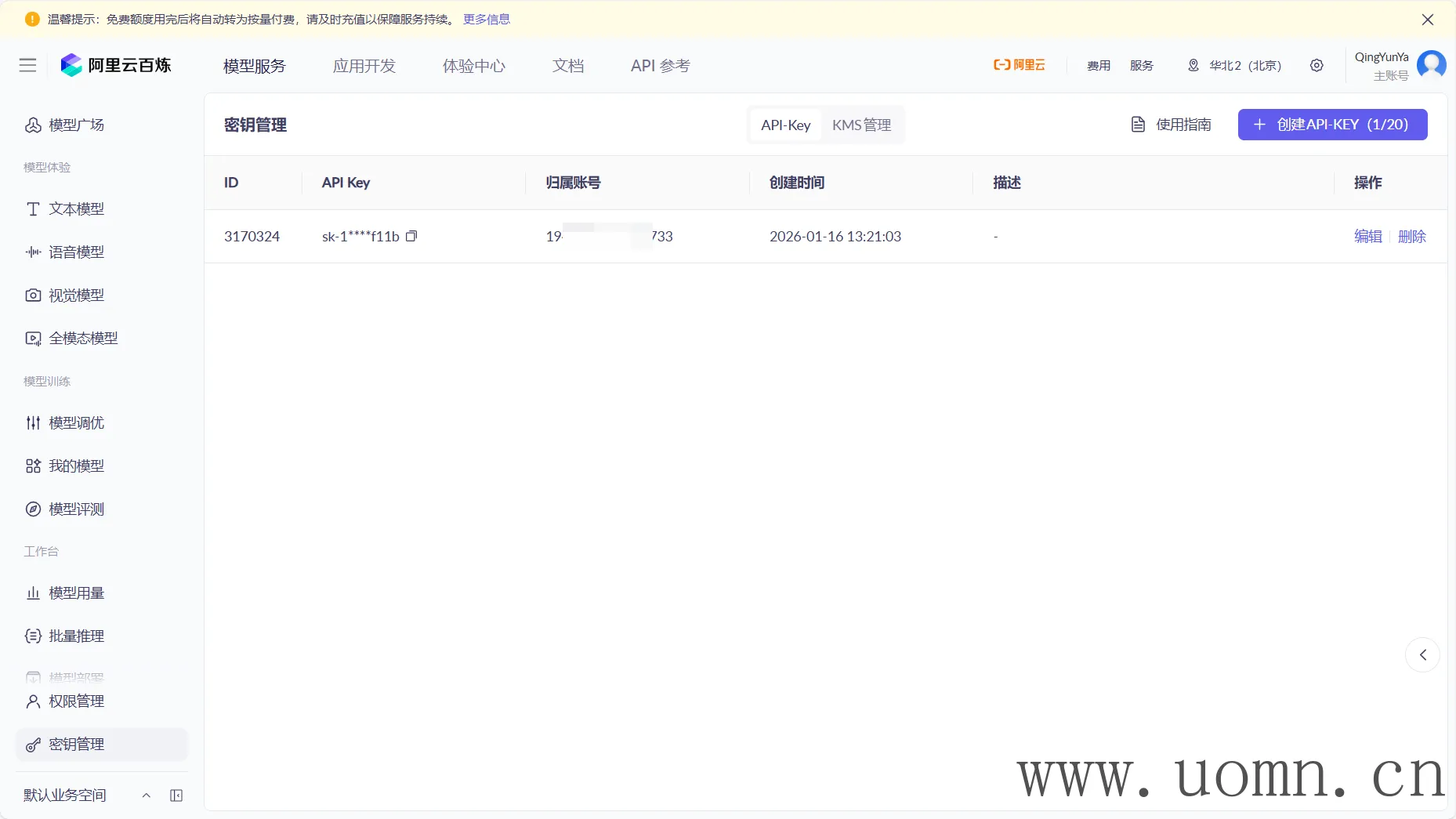
关于模型选择,只要有阿里百炼图标的都选上,如下图
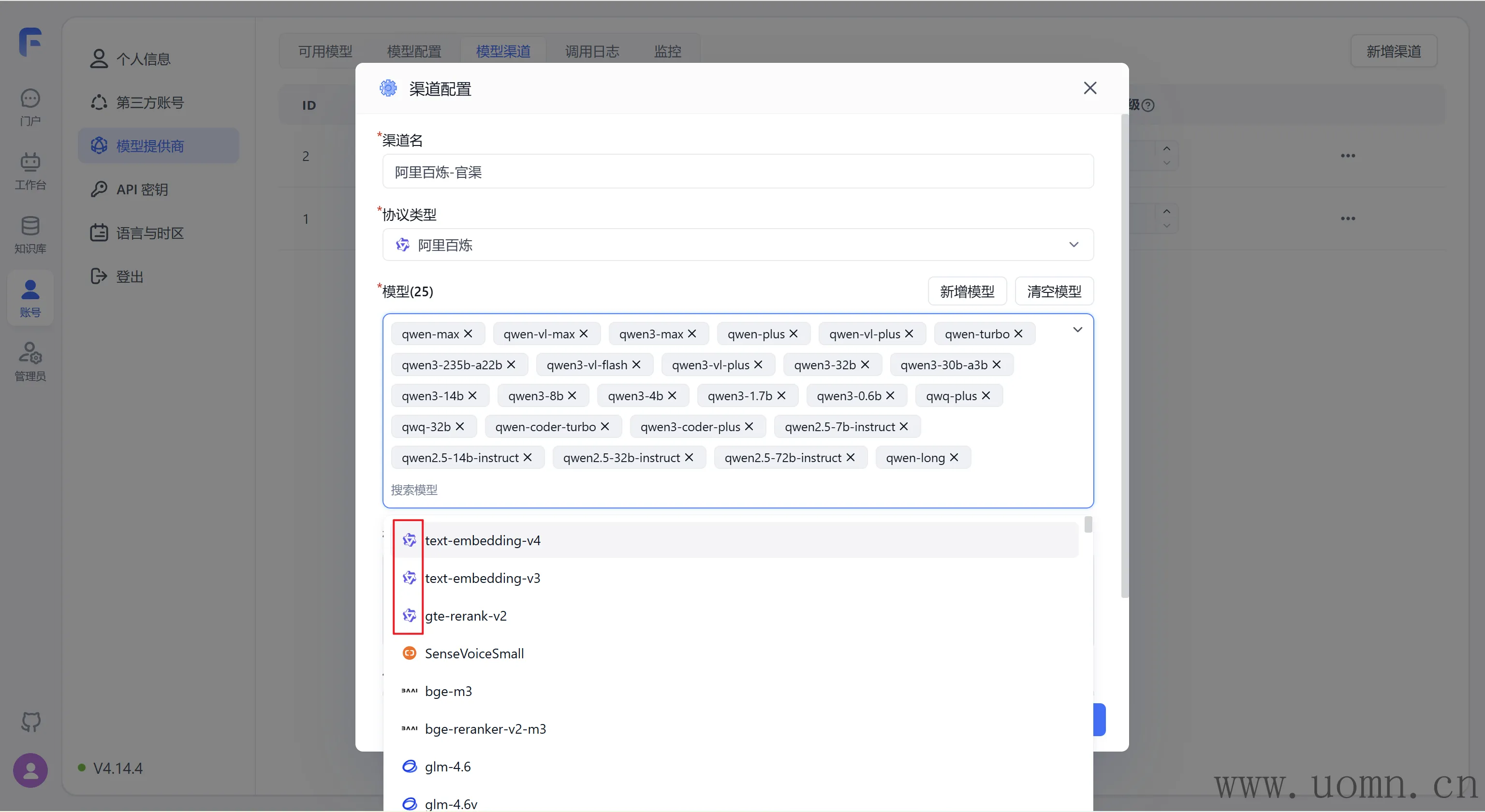
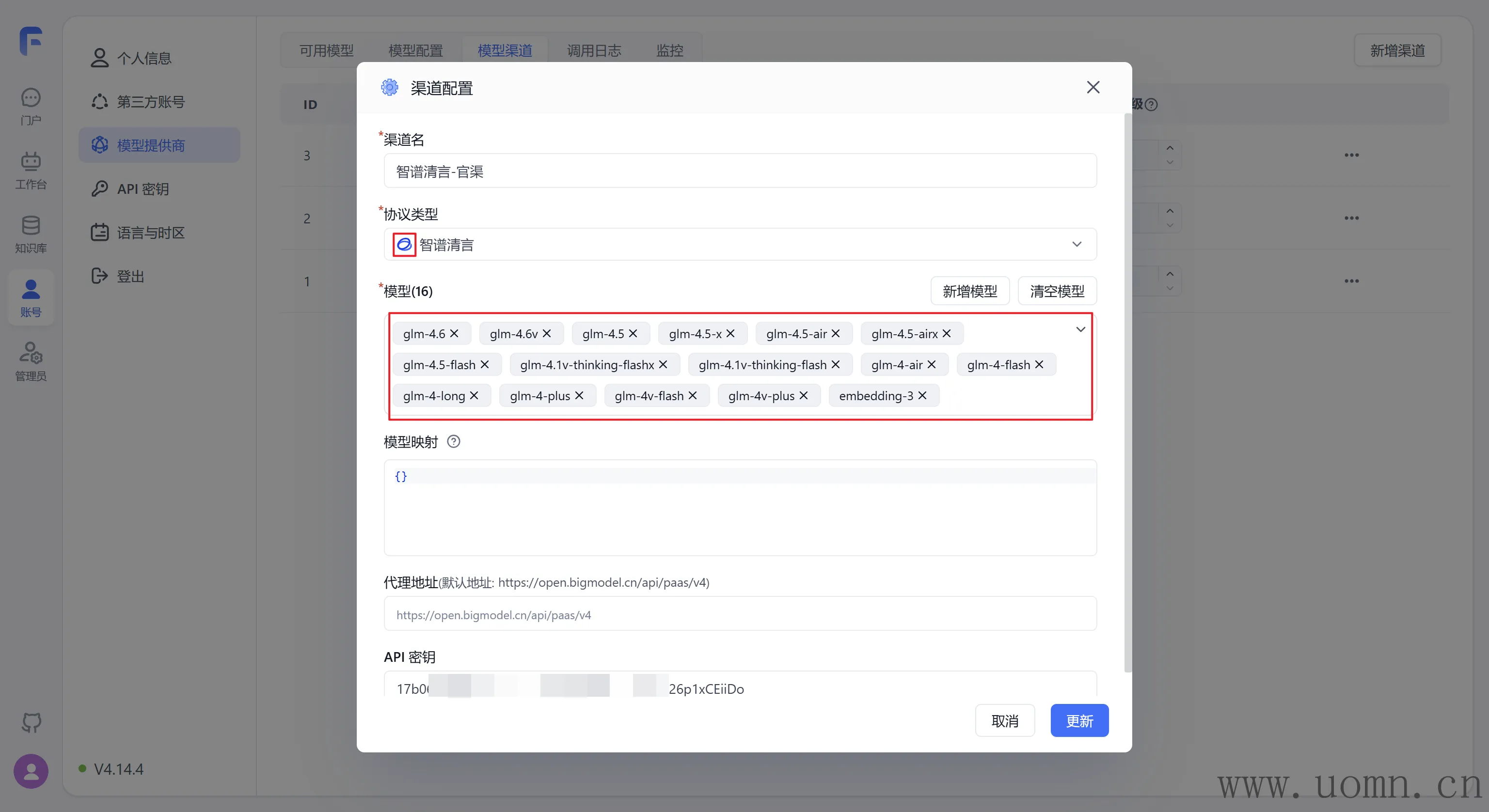
智谱清言
关于模型选择,只要有智谱清言的图标的模型都选上
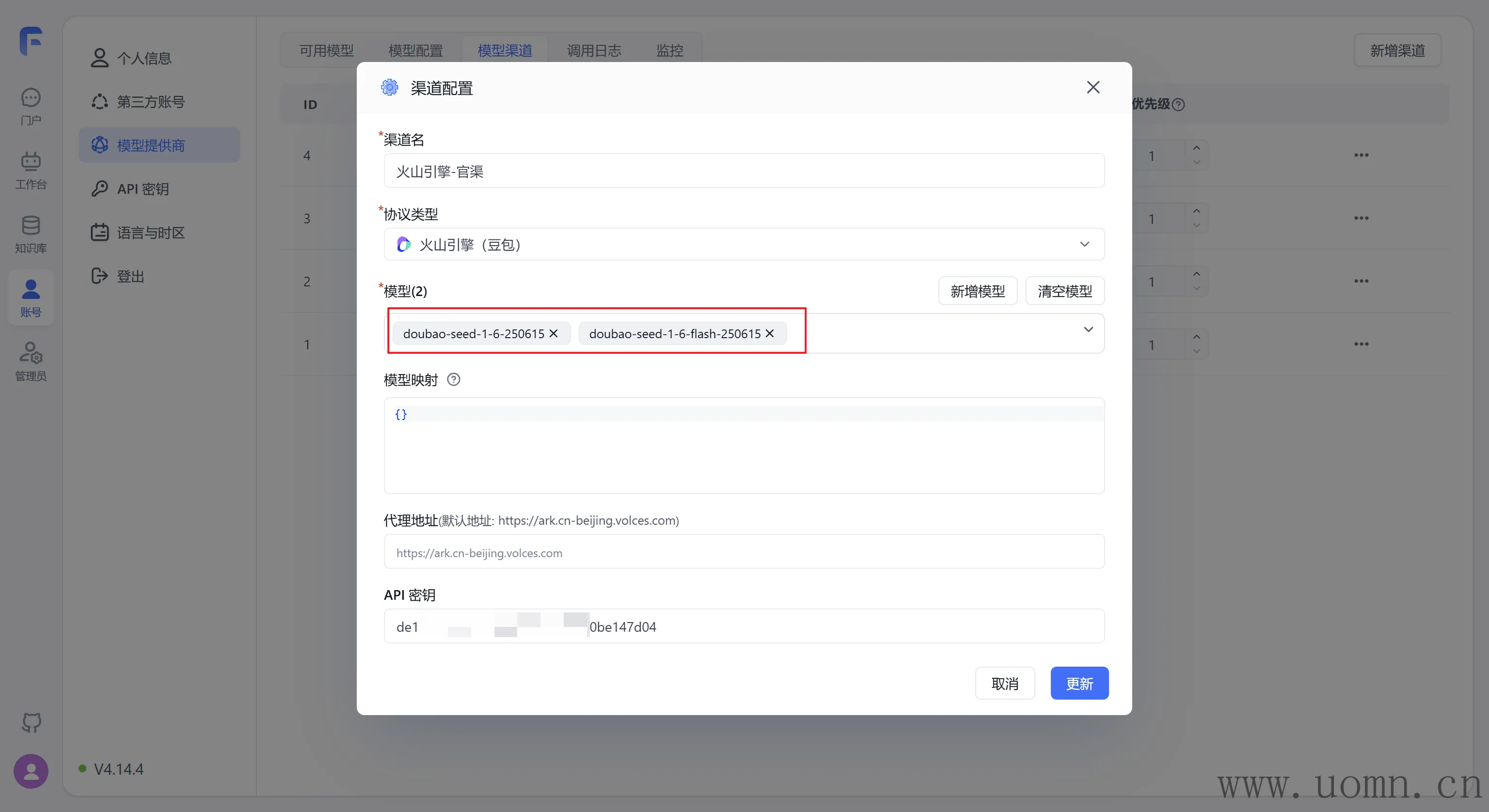
火山方舟(豆包)
在创建API密钥前,需要开通所有的大模型
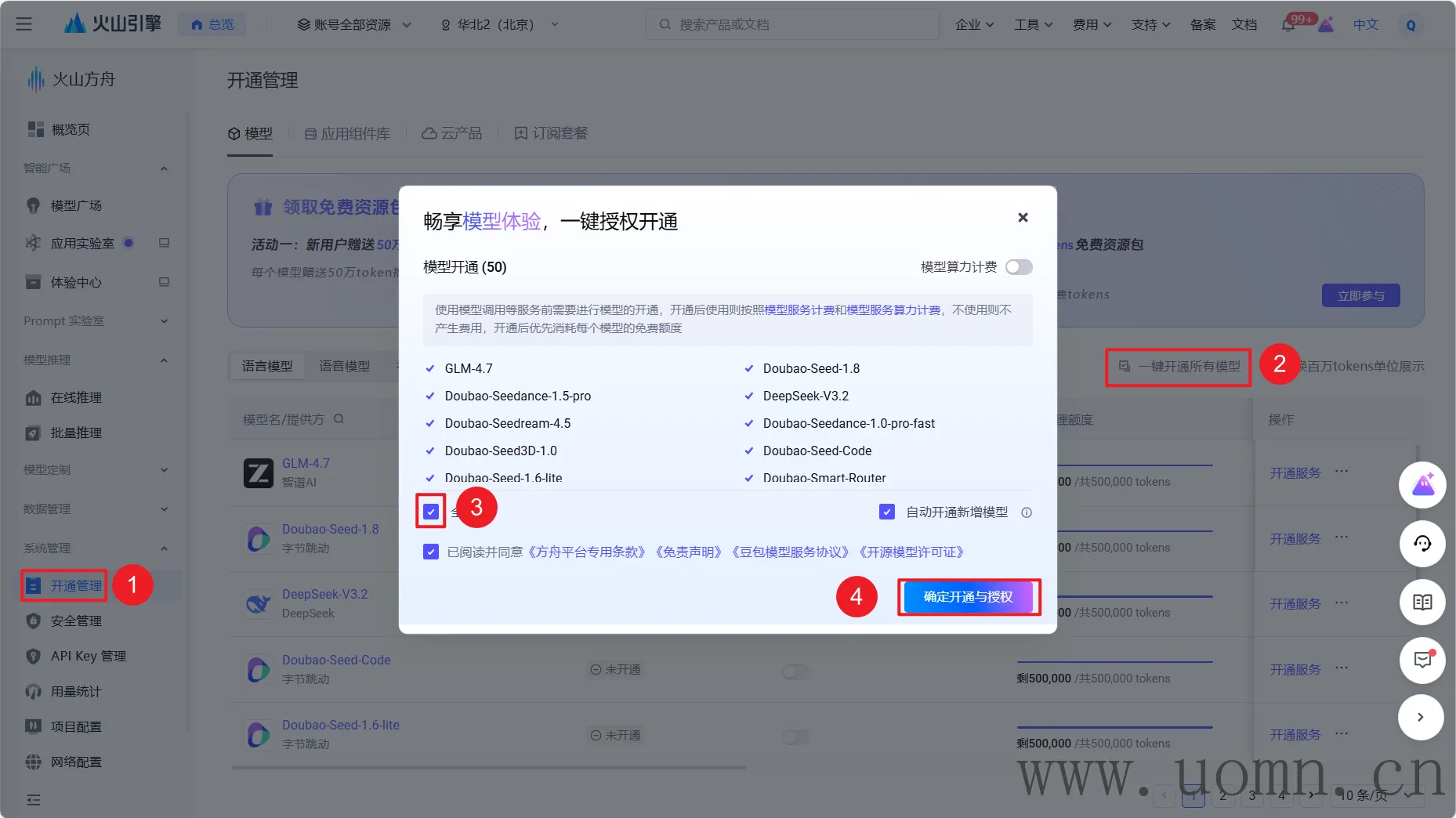
刚测试了一下,发现FastGPT内预设的模型只支持doubao-seed-1-6-250615 和doubao-seed-1-6-flash-250615 ,所以暂时只选择这两个模型
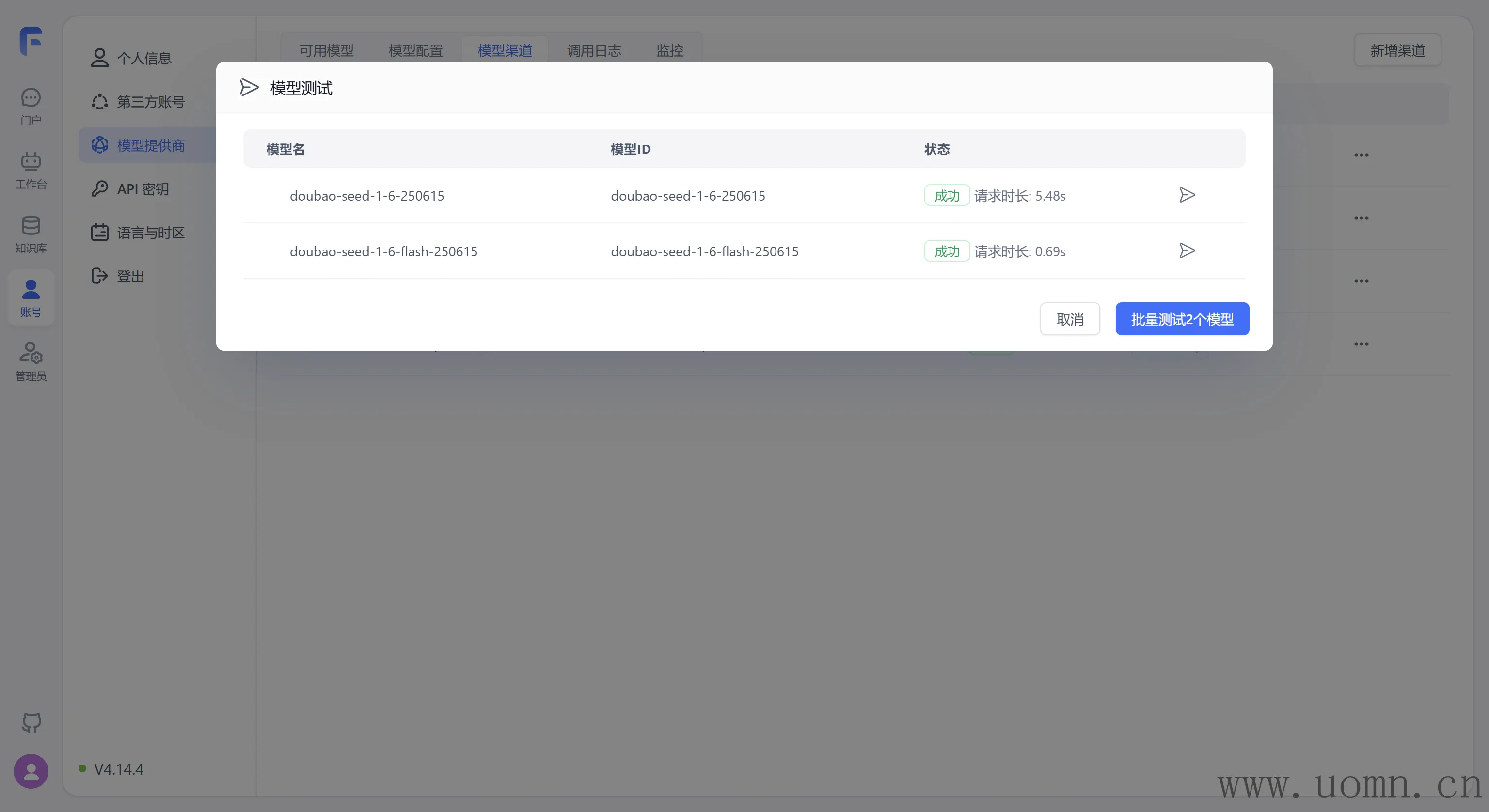
国外模型
国内模型大概就上边4个服务商比较常用,国外模型这里我使用的是中转API,我这里也没帐号啥的,所以不方便写那些国外模型的教程,直接用中转API了就,下边推荐一个我个人感觉比较好的中转API
这里会接入截图中4个服务商的模型
一般创建账号后会自动生成一个API,用那个就行
协议类型选择:OpenAI
在代理地址处填写:https://api.hallucodex.com/v1 (下边截图里忘记带/v1了,懒得重新截图了)
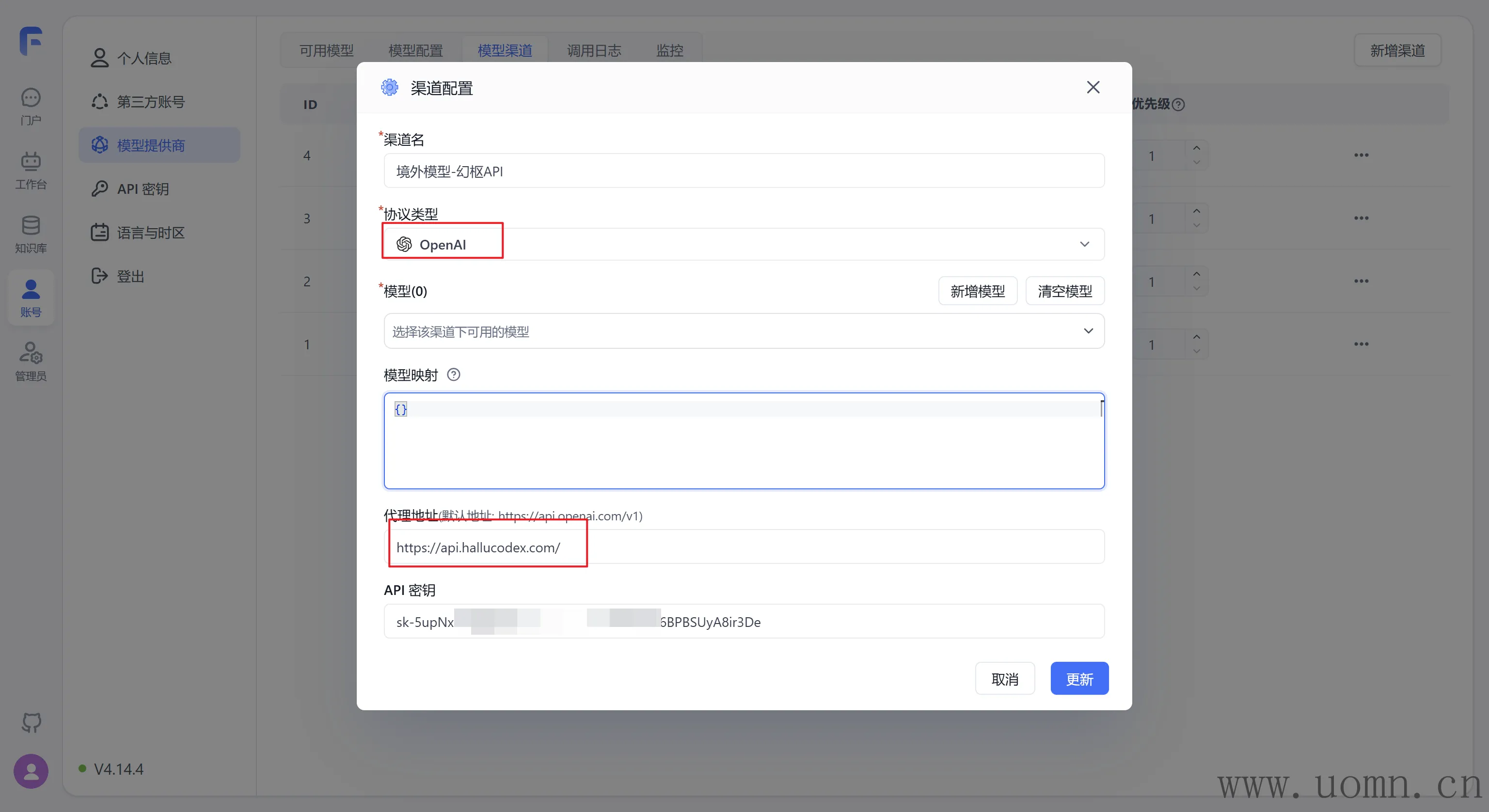
至于模型选择这里,可以先查看中转API的模型列表,看要用哪些,然后选上就行
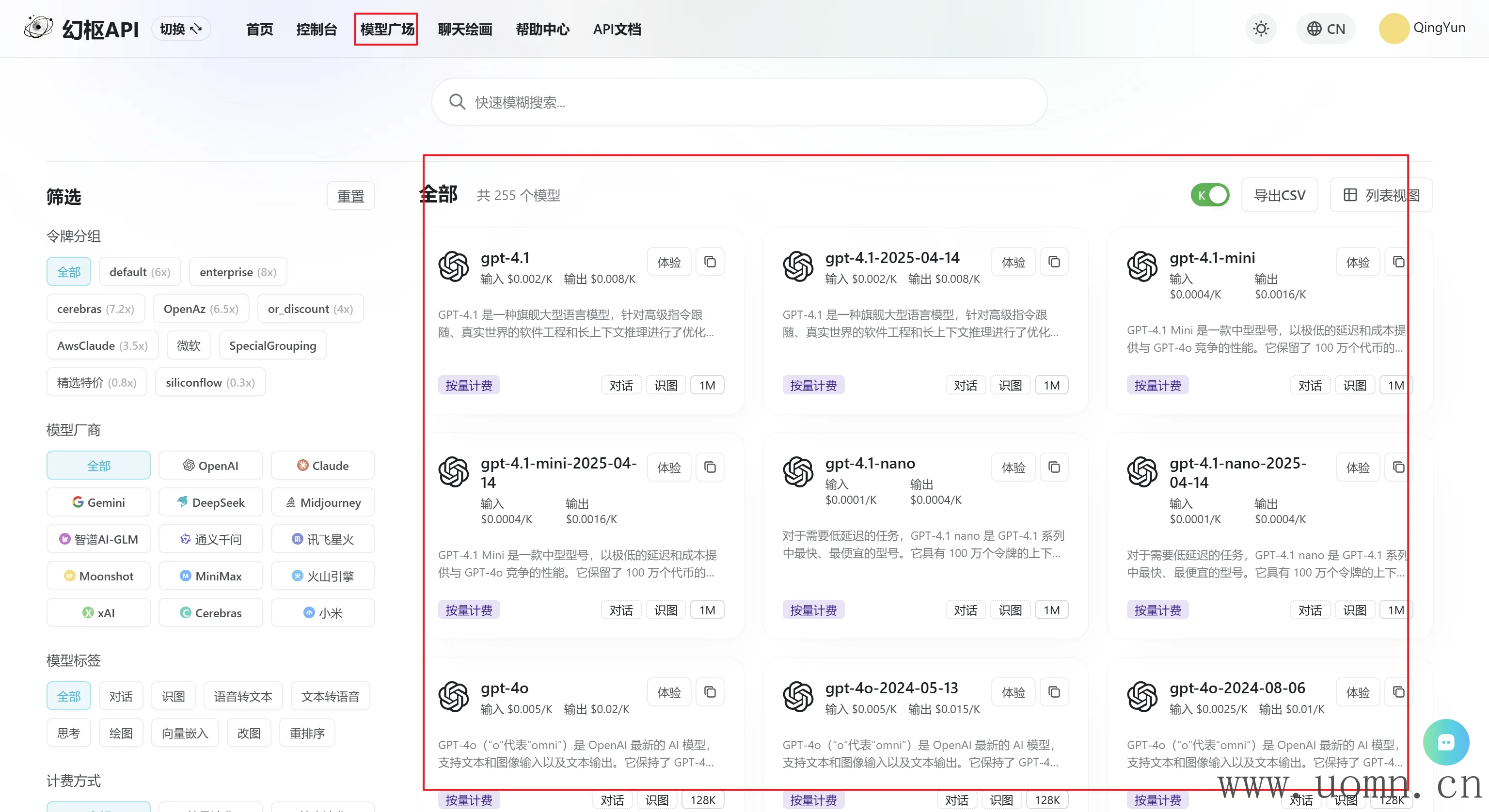
我这里选了几个个人比较常用的
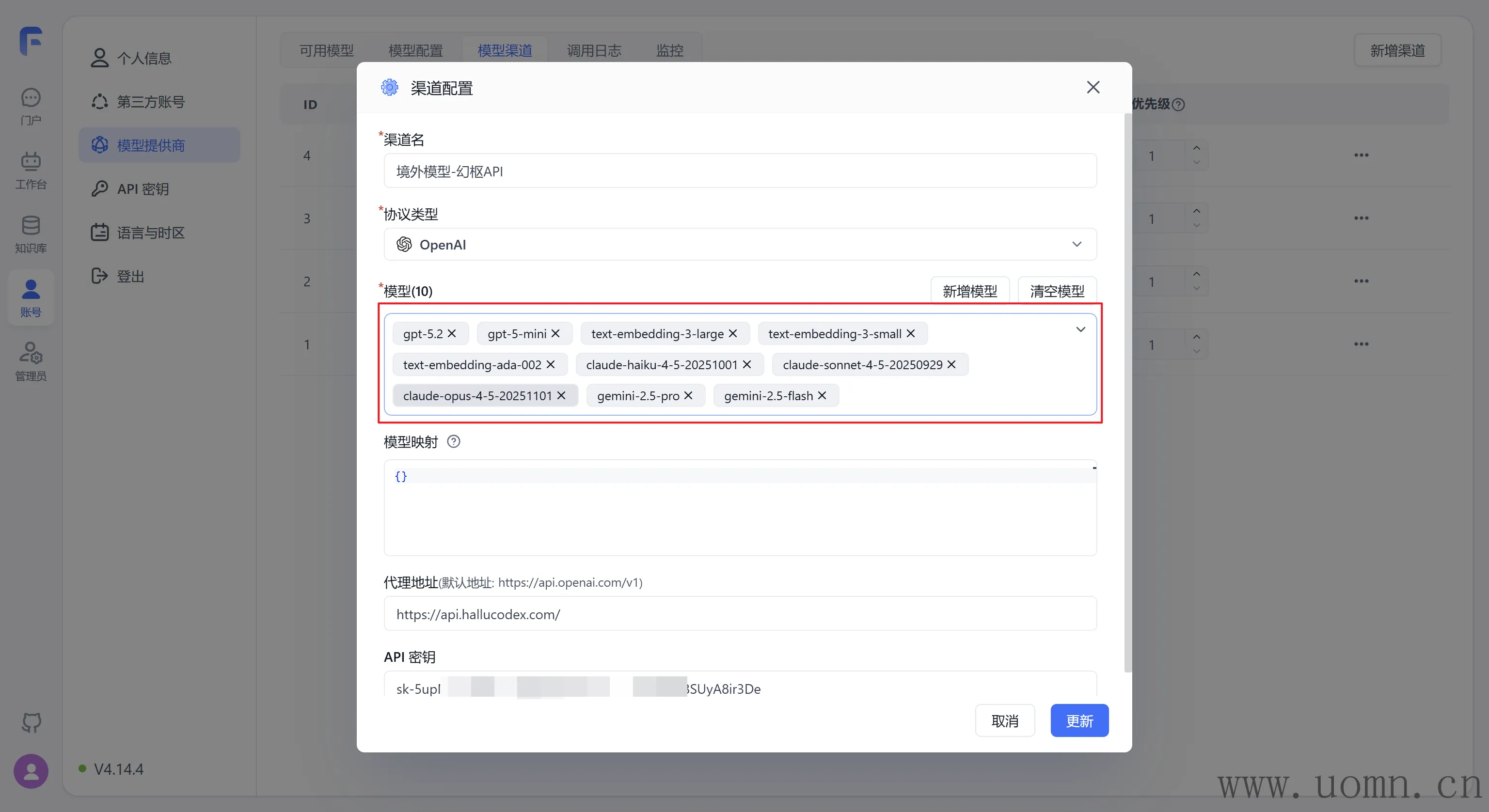
选完模型测试下能不能用
本地模型部署
上边说完了在线模型的接入,接下来就是接本地的模型了,这里使用Ollama来部署
由于我个人电脑只有一个8G的显卡,所以教程里只能用一些拉一点的模型
安装Ollama
以Docker方式安装Ollama更方便一点,所就以Docker部署来写
之前使用FinalShell连接了本地的Ubuntu,现在需要打开这个SSH工具并连接好,执行下放命令
# 拉取Ollama
docker pull ollama/ollama
# 查看FastGPT所在网络
docker inspect -f '{{.NetworkSettings.Networks}}' fastgpt
# 运行Ollama并加入到FastGPT的网络
docker run -d \
--name ollama \
--network <网络名> \
-p 11434:11434 \
-v ollama_models:/root/.ollama \
--restart unless-stopped \
ollama/ollama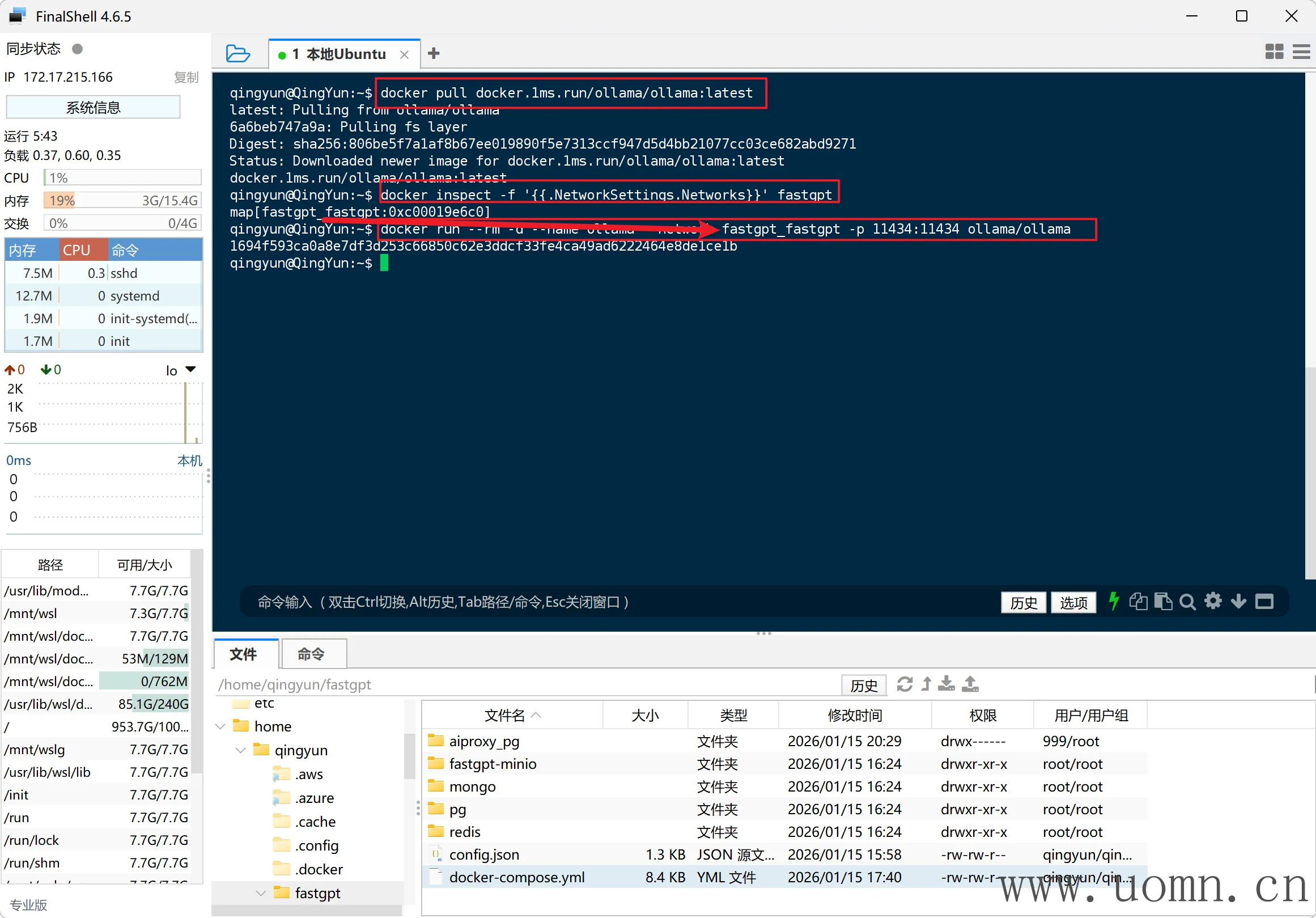
拉取模型
可在Ollama官网查找可用模型及模型部署命令
下放为教程示例:按序执行下方命令进入
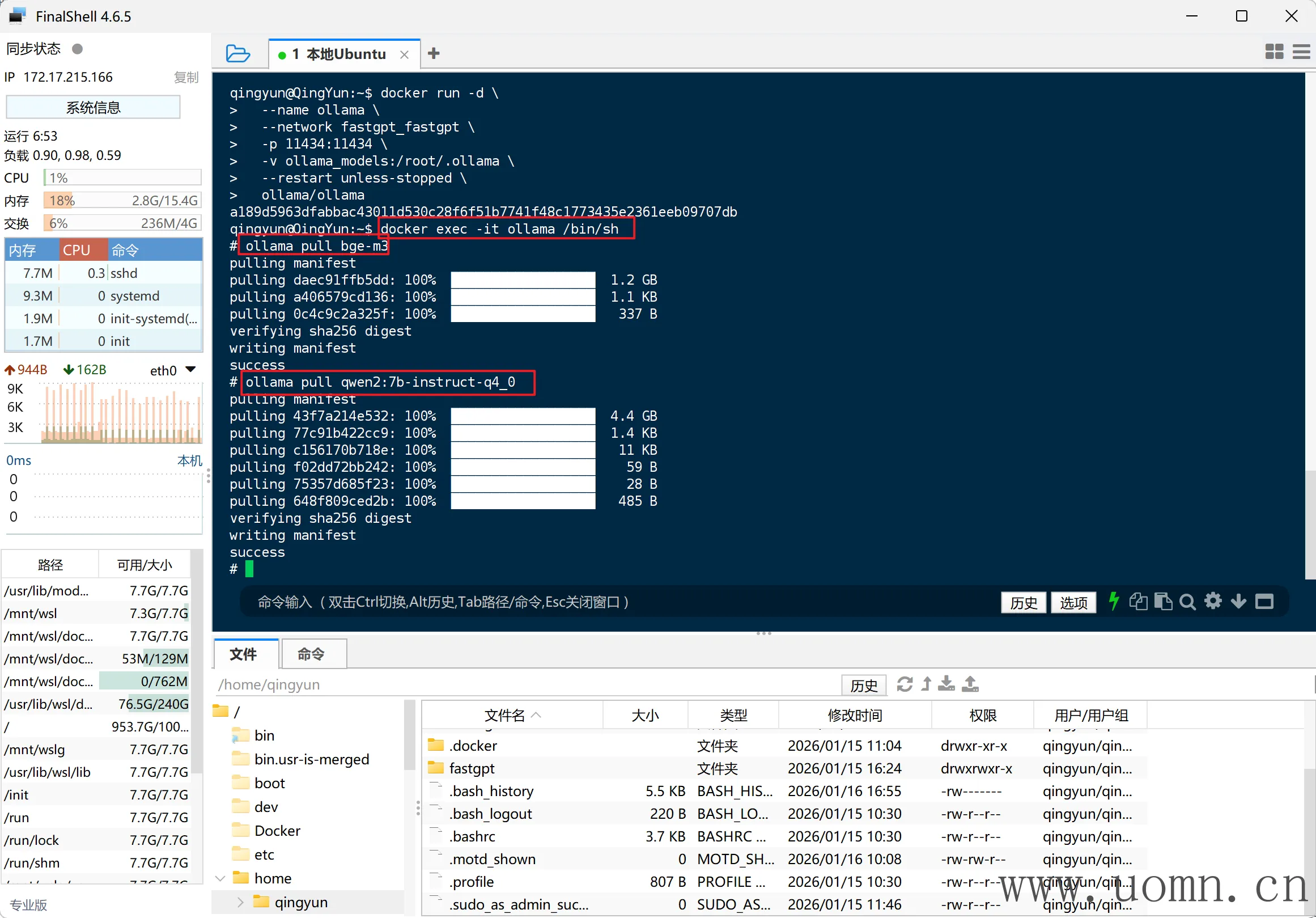
# 进入Ollama终端
docker exec -it ollama /bin/sh
# 拉取bge-m3模型(文本嵌入&重排)
ollama pull bge-m3
# 拉取qwen2.5:7b(文本生成)
ollama pull qwen2.5:7b后边为了方便接入FastGPT,我把文本模型改为了qwen2.5:7b ,下图中是我之前拉的别的模型,我就不重新截图了
GPU加速大模型
目前使用ollama是使用的内存跑的,效果可能会差一点,所以这里开始配置使用显卡跑大模型
查看显卡信息
我的显卡是4060,8G显存;内存是32G;
要求显卡驱动版本≥535+,低于此版本先更新一下驱动哈
然后Win+R输入cmd打开命令行窗口,输入下方命令,有信息就没问题
# 进入Ubuntu
wsl
# 查看显卡信息
nvidia-smi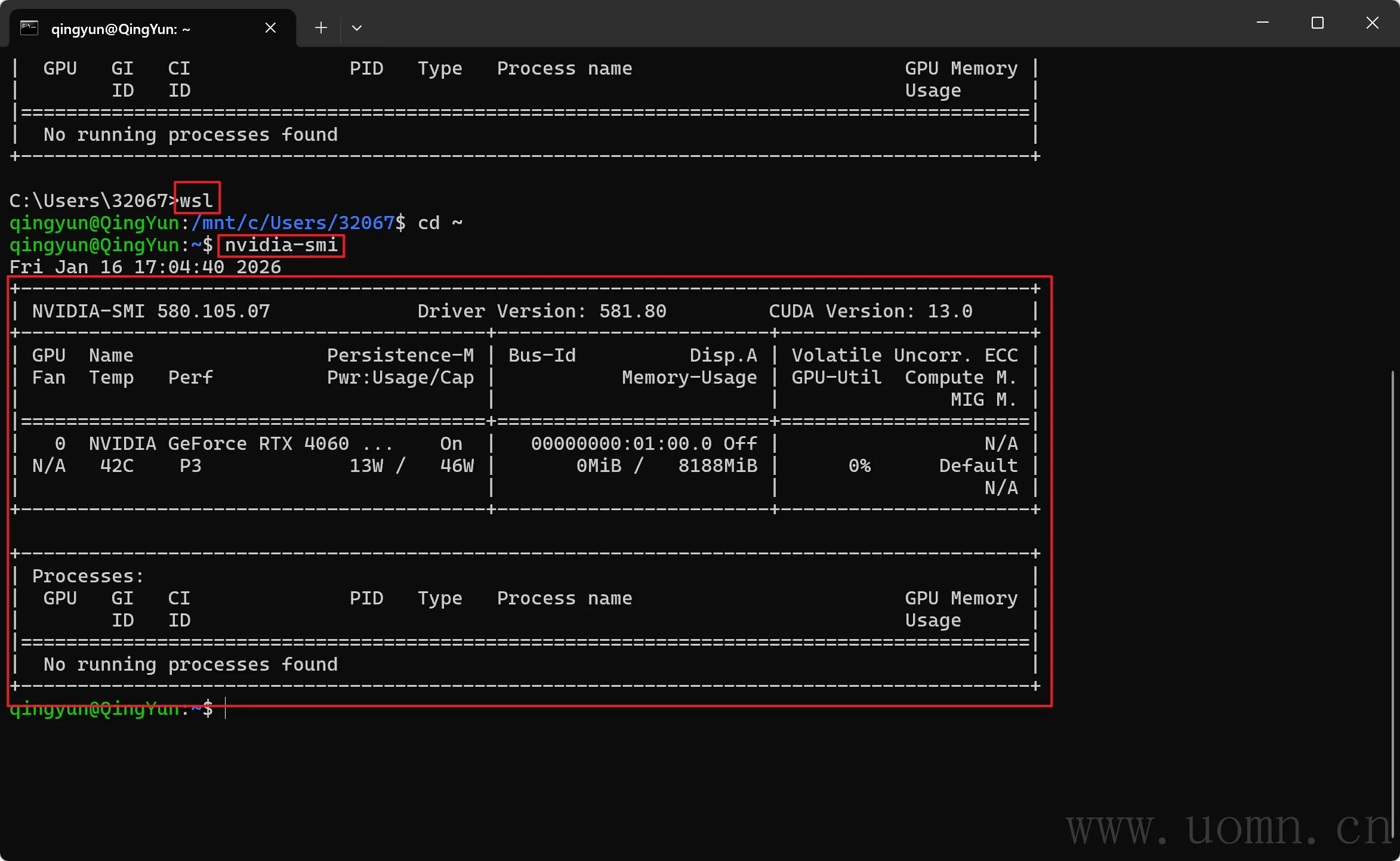
带GPU启动Ollama
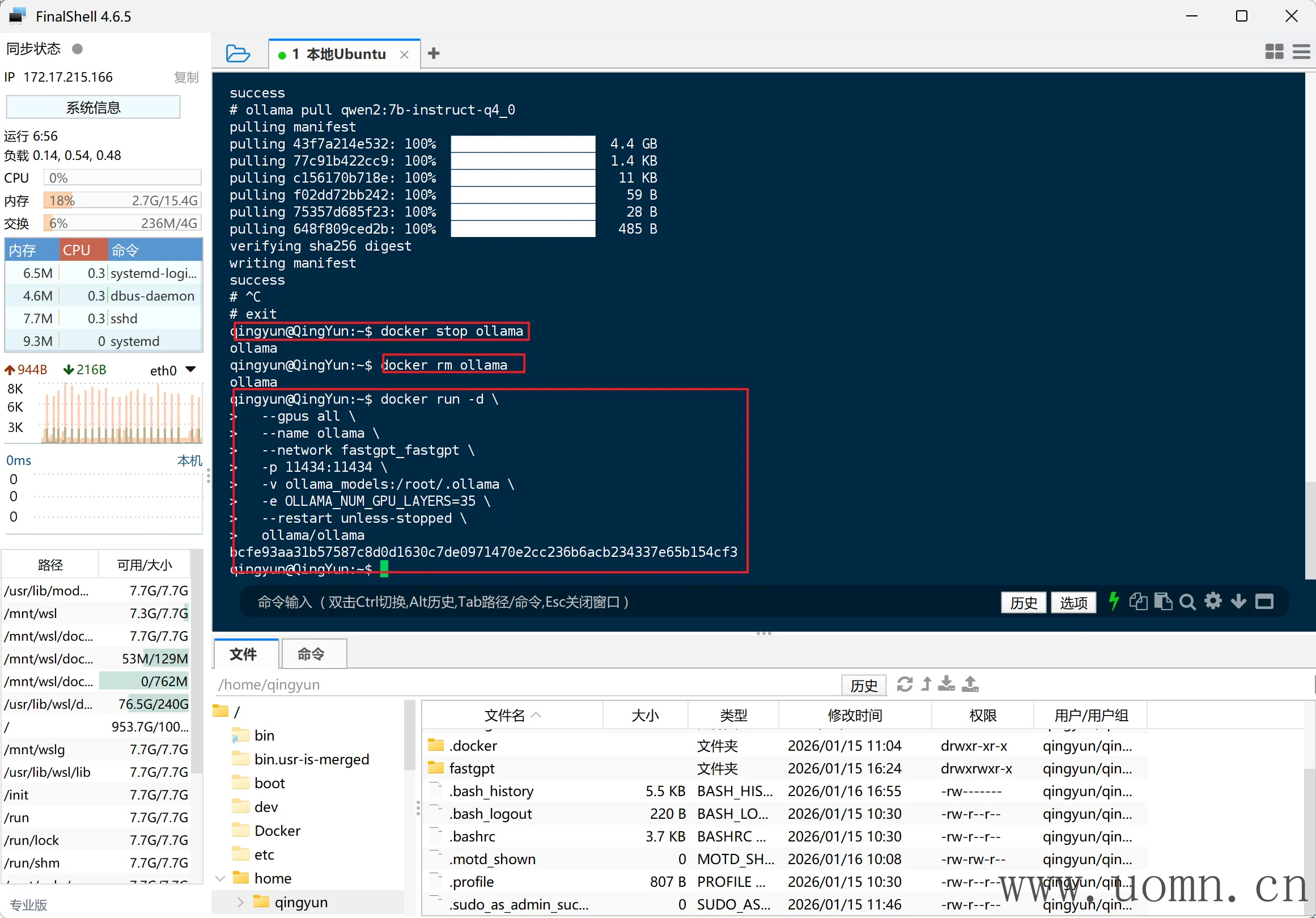
返回FinalShell工具,按序执行下方命令
# 停止容器
docker stop ollama
# 删除容器
docker rm ollama
# 带GPU启动
docker run -d \
--gpus all \
--name ollama \
--network fastgpt_fastgpt \
-p 11434:11434 \
-v ollama_models:/root/.ollama \
-e OLLAMA_NUM_GPU_LAYERS=35 \
--restart unless-stopped \
ollama/ollama部分参数说明
--gpus all:启用所有 NVIDIA GPU(WSL2 + Docker Desktop 支持)
-e OLLAMA_NUM_GPU_LAYERS=35:将模型的 35 层卸载到 GPU(适合 RTX 4060 8GB)
如果你跑更小的模型(如
phi3、gemma:2b),可设为40+如果显存不足报错,降低此值(如
30)
可选参数
-e OLLAMA_KEEP_ALIVE=-1 \ :模型加载后永远不卸载,其他值:5m(5分钟)、1h(1小时)、0(立即卸载)
说明一下:ollama在启动模型的时候,会将一部分文件预加载到内存/闪存中,然后才能开始对话,当一段时间没有交互后,则会把这些文件卸载释放资源。这就会导致下次使用的时候还得重新花时间加载,根据自己的需求选择。
测试效果
# 进入Ollama终端
docker exec -it ollama /bin/sh
# 跑一下模型,随便问一个问题
ollama run qwen2.5:7b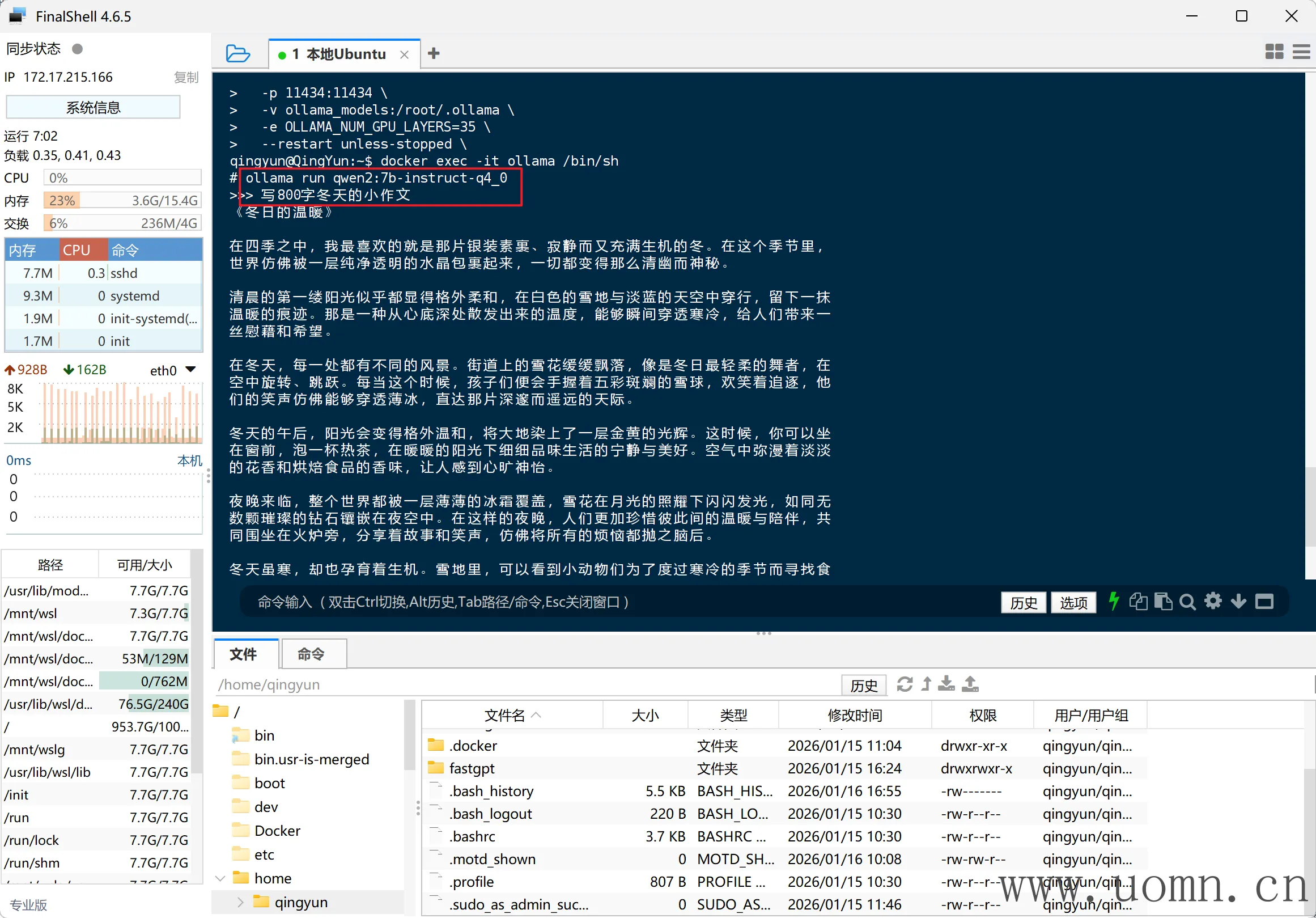
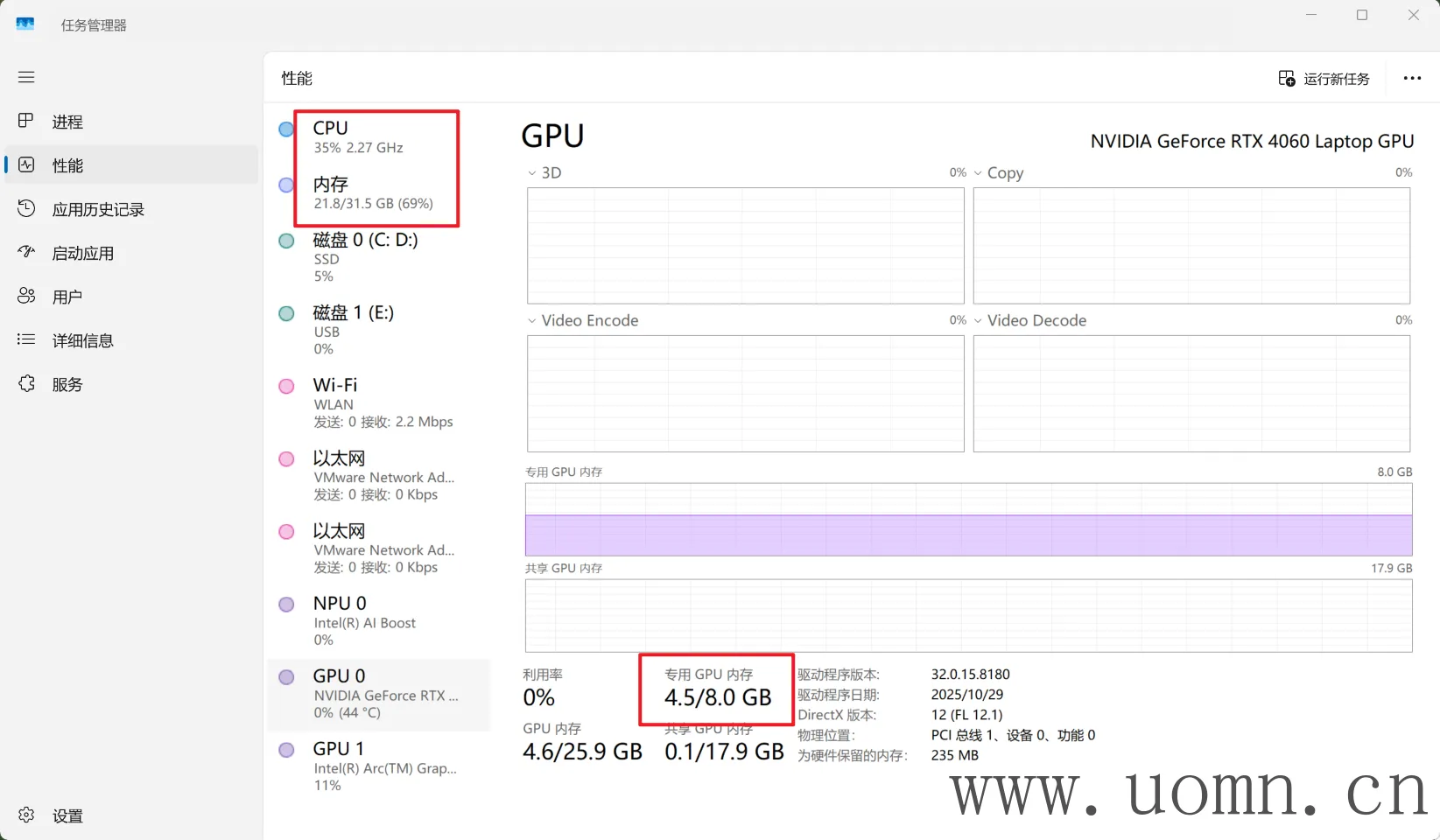
当执行Run命令后,如果在显卡工作的情况下,CPU的占用率是跑不满100%的,同时显卡上有现存被占用,根据上图可以看出,我的显存只用了4.5GB,说明在启动Ollama的时候OLLAMA_NUM_GPU_LAYERS 的值还能调的更高(之前是35)
如果你们在测试的时候也这样,那么就可以像上边那样停止&删除容器,然后调高OLLAMA_NUM_GPU_LAYERS 参数的值,再次启动,每次建议+5,加多了容易爆闪存
当然,部分模型的层数可能低于35层,也就是说即使你调高了启动时的参数,占用可能依旧不变
本地模型接入FastGPT
本地模型的接入和在线模型的差不多,都是需要新增渠道
协议类型选择Ollama
模型就选择上边ollama pull <模型名>的模型名,也可以选择先看模型名,再去Ollama的网站找对应的部署模型的命令
渠道配置里的模型名一定要和部署模型时候的模型名一致,要不然会提示模型不存在的
代理地址填容器名+IP,不要使用localhost或127.0.0.1,会连不上。示例:http://ollama:11434
API密钥随便填就行这个
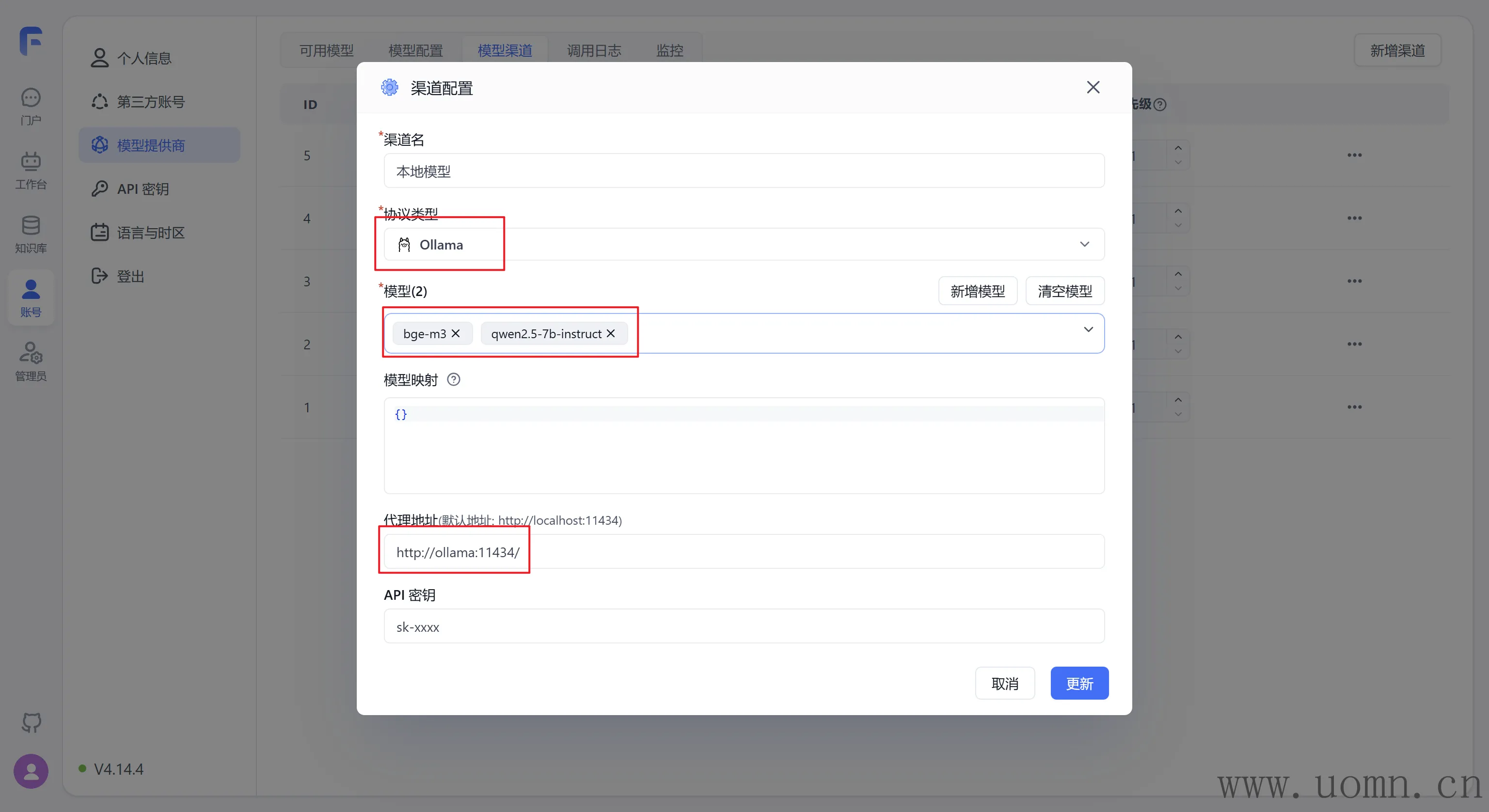
弄好之后测试一下就行了
其他说明
大多数情况下,Ollama里的模型名称在FastGPT中对不上,这个时候就得新增模型了
需要根据模型的类型去选择
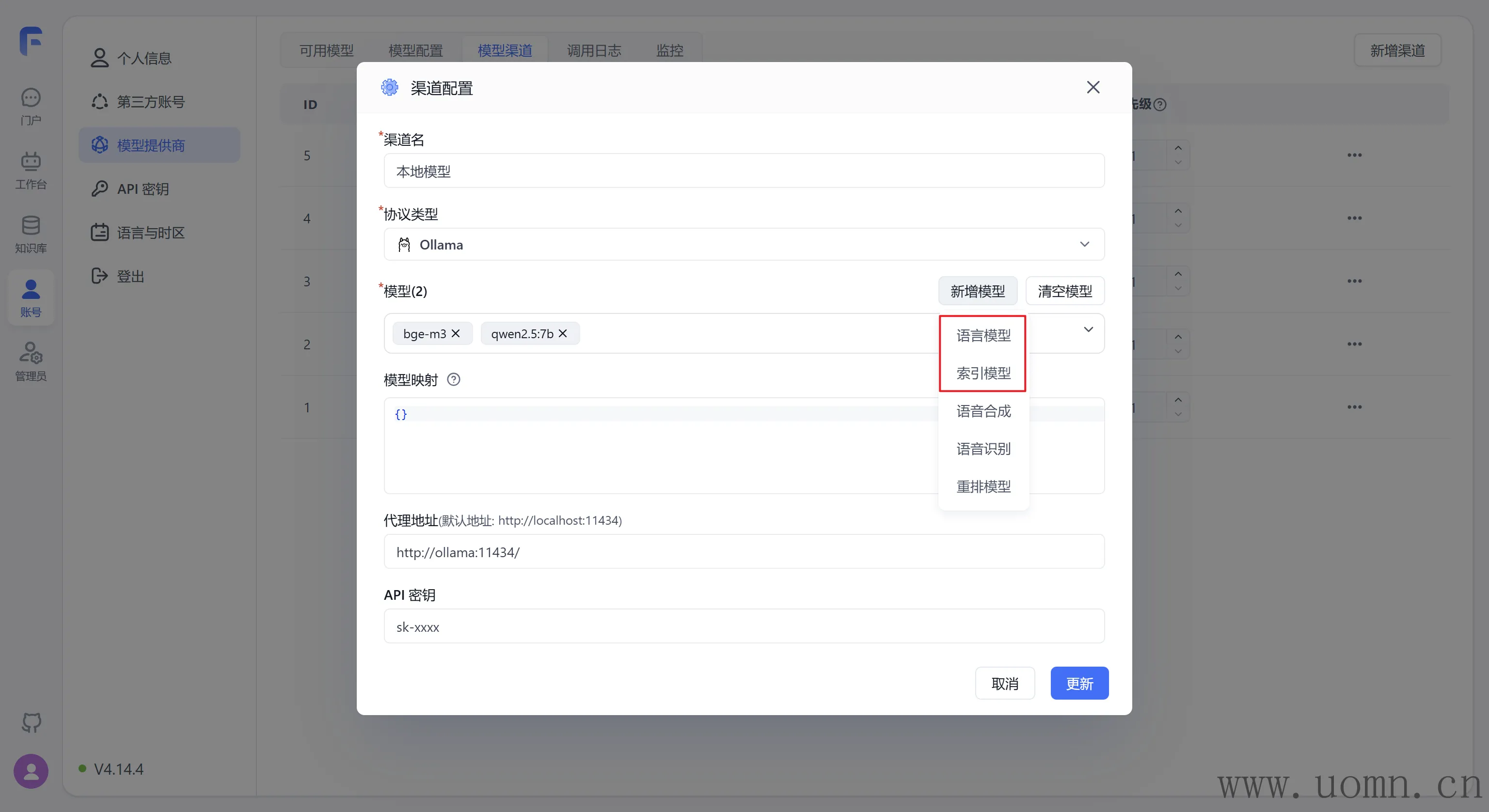
例如,这个qwen2.5:7b模型,在FastGPT里边就没有对应的,这是语言模型,那就新增一个语言模型
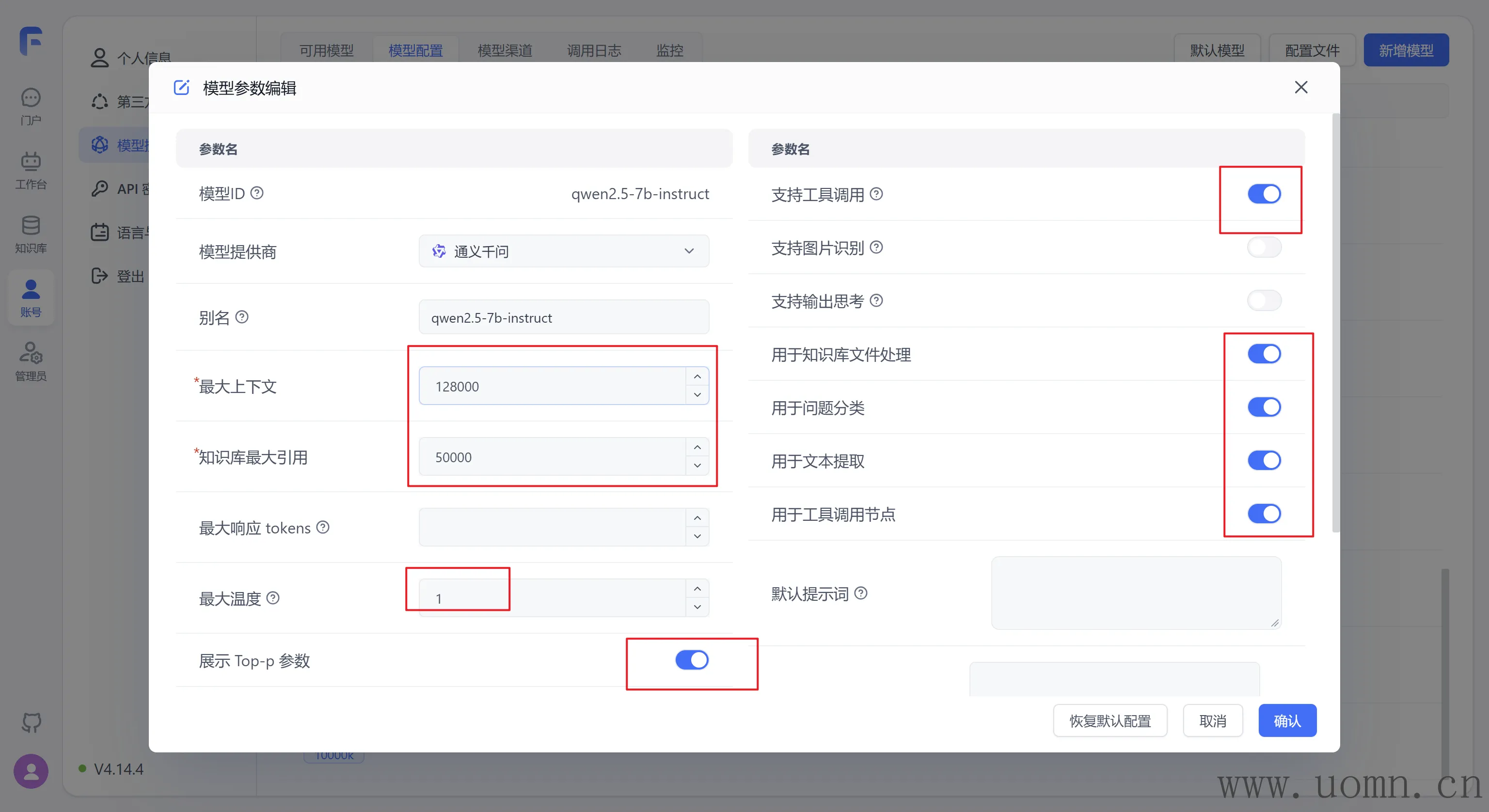
以qwen2.5:7b为例
在模型ID处填写模型名:qwen2.5:7b,用于实际请求携带的参数
模型提供商显而易见的就是:通义千问
别名是给用户看的名称,别名里边不要用冒号:qwen2.5-7b
什马?剩下的参数不知道怎么写?抄就完了!在通常上找到一个差不多的模型,把数值抄过来就能用了
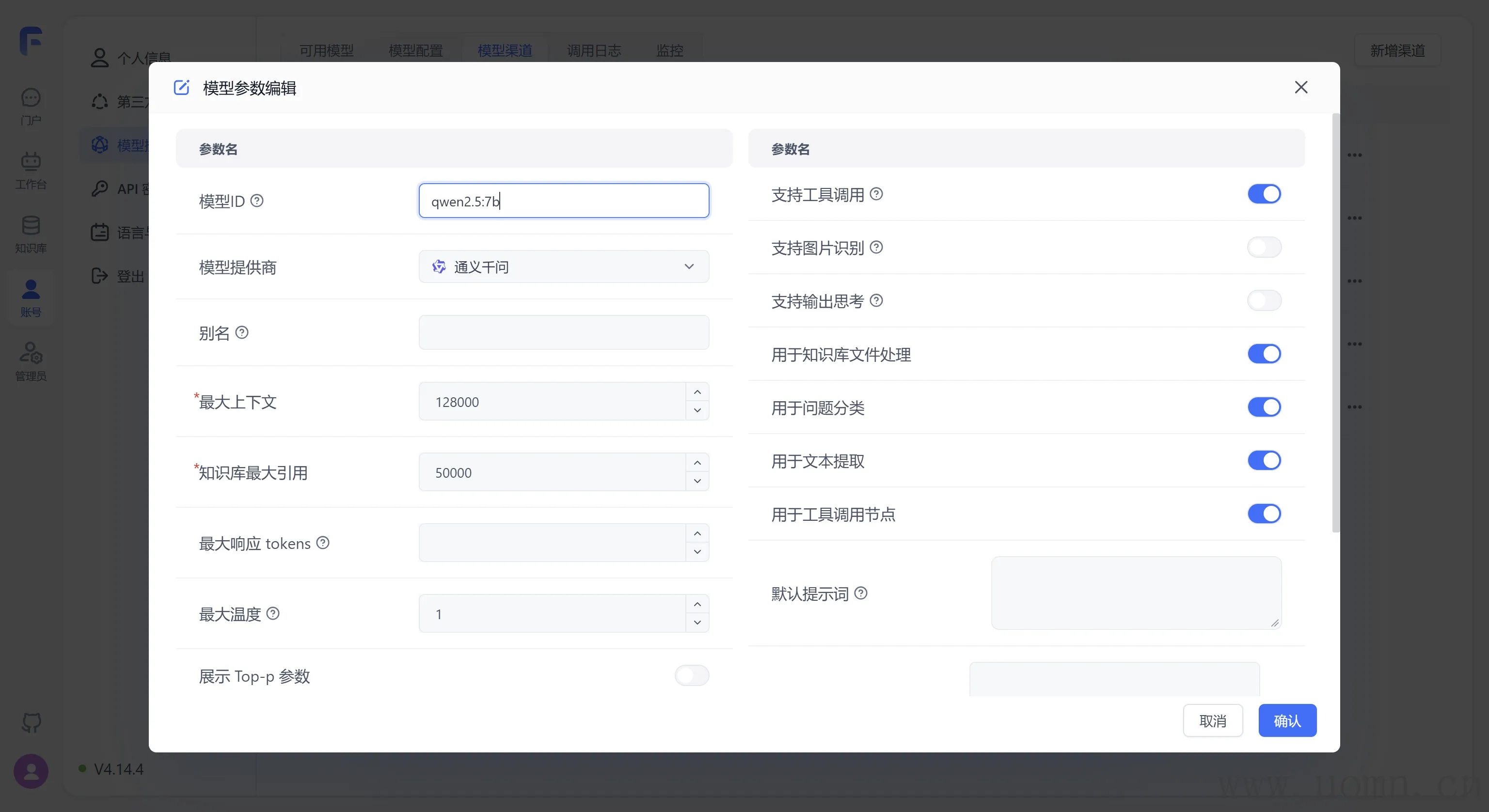
与我新增的模型同样都是通义千问,同样是2.5版本,同样是7b的参数
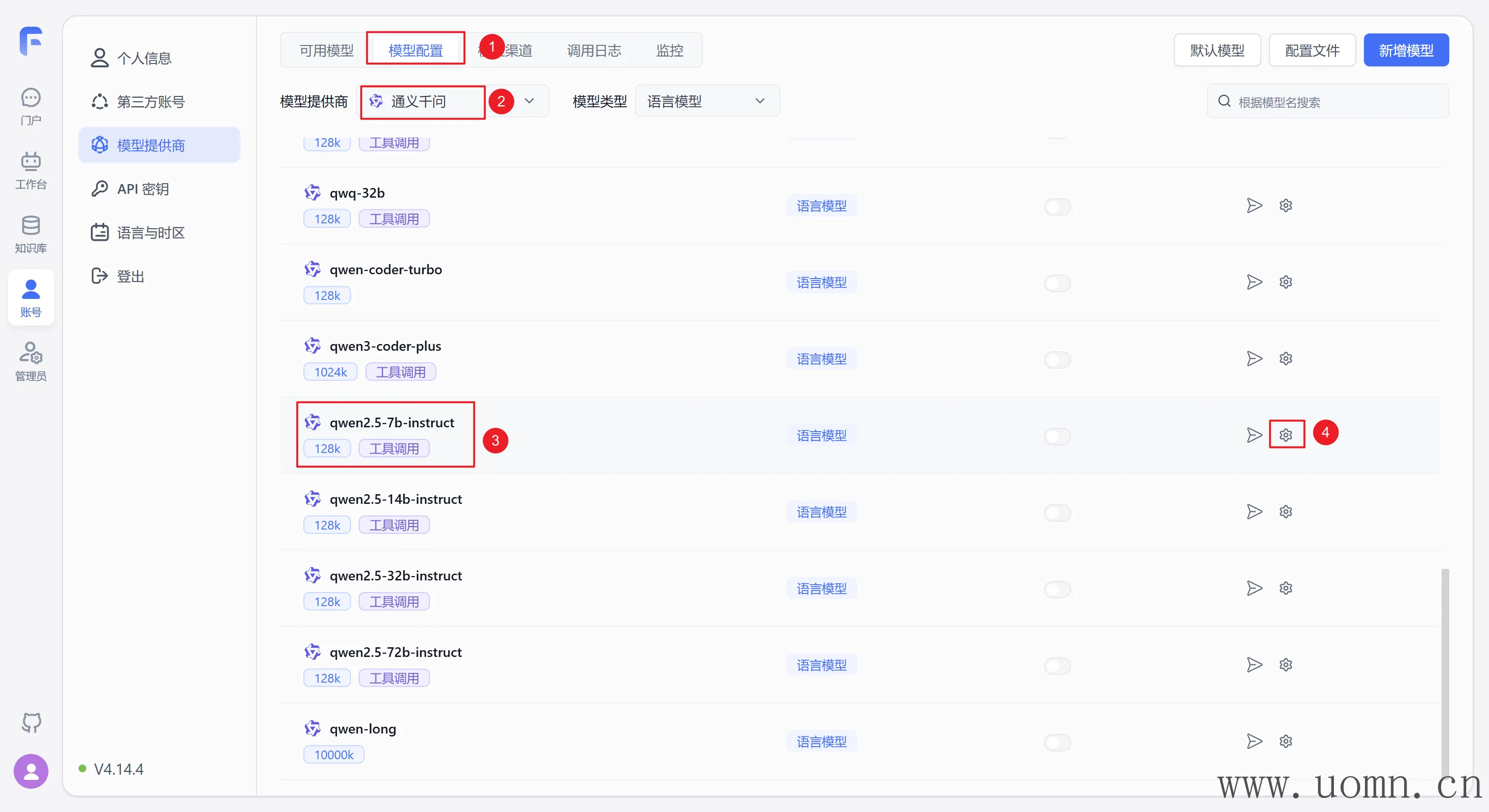
它的参数是怎样的,那么就在新增的模型里怎么设置参数
模型渠道优先级说明
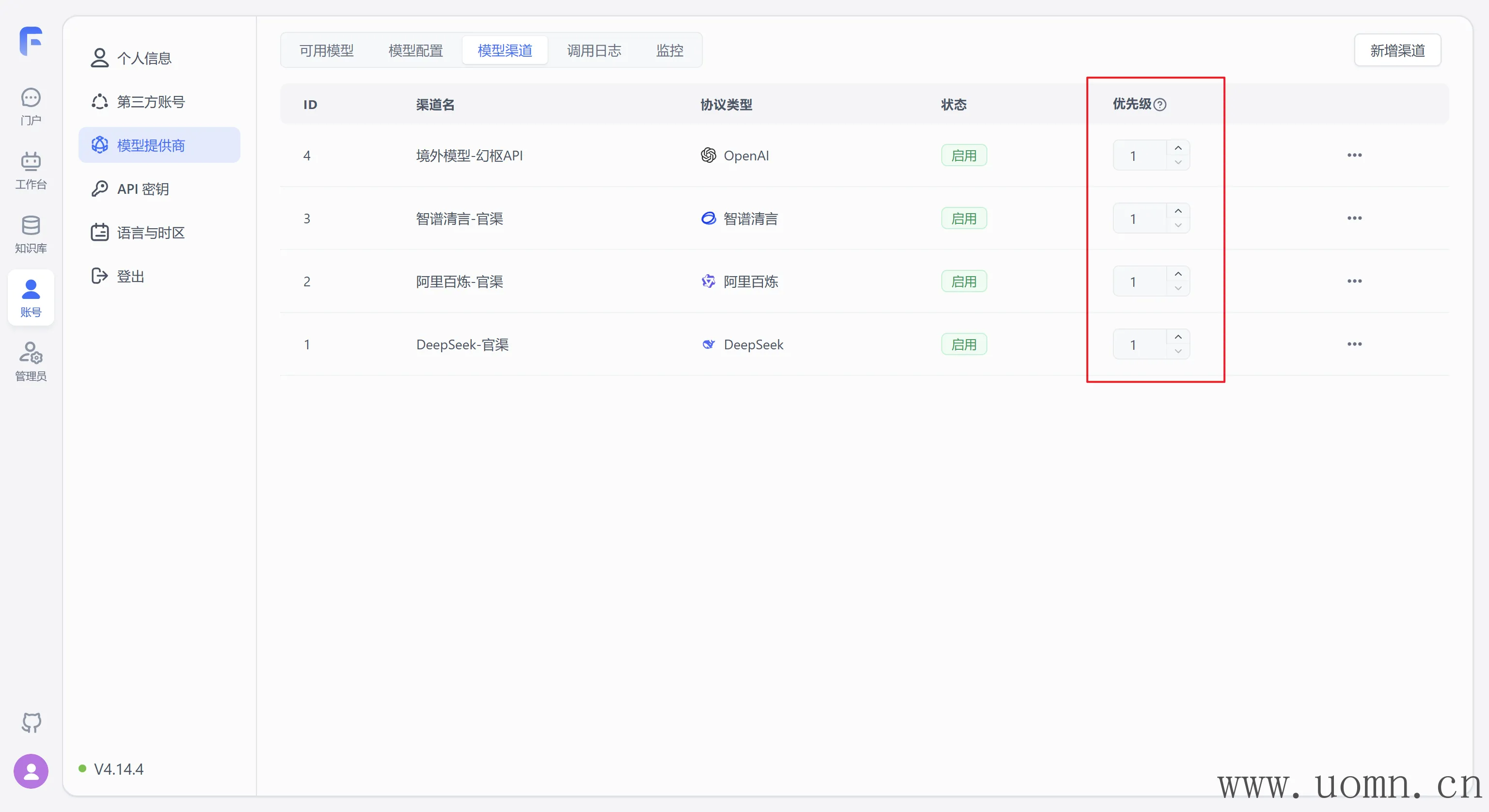
数字越大,优先级越高
当两个模型渠道都包含同一个模型时,系统会自动按照优先级去选择模型的渠道,优先级高的渠道更容易被选择
例如,我在OpenAI官方渠道接入了一个GPT-4o-mini,同时在中转渠道也接入了一个GPT-4o-mini,假设官方渠道优先级为99,中转渠道优先级为1,那么在后续使用GPT-4o-mini模型的时候。若使用了100次,则官方渠道调用99次,中转渠道调用1次。
当然这是为了方便理解才这么说的,具体多少次,概率问题
一般的使用场景:对同一个模型有多个渠道,每个渠道的并发、价格都不一样,那么并发高的或者价格低的,就可以把优先级调整的更高,以应付更高的并发或消耗更低的价格。
启用模型
虽然已经添加完了渠道,但是模型依旧需要启用之后才能调用
启用的模型确保已经在渠道中选中了
注意:新增的自定义模型会自动启用
这里每个渠道都选一个测试,启用方法如下
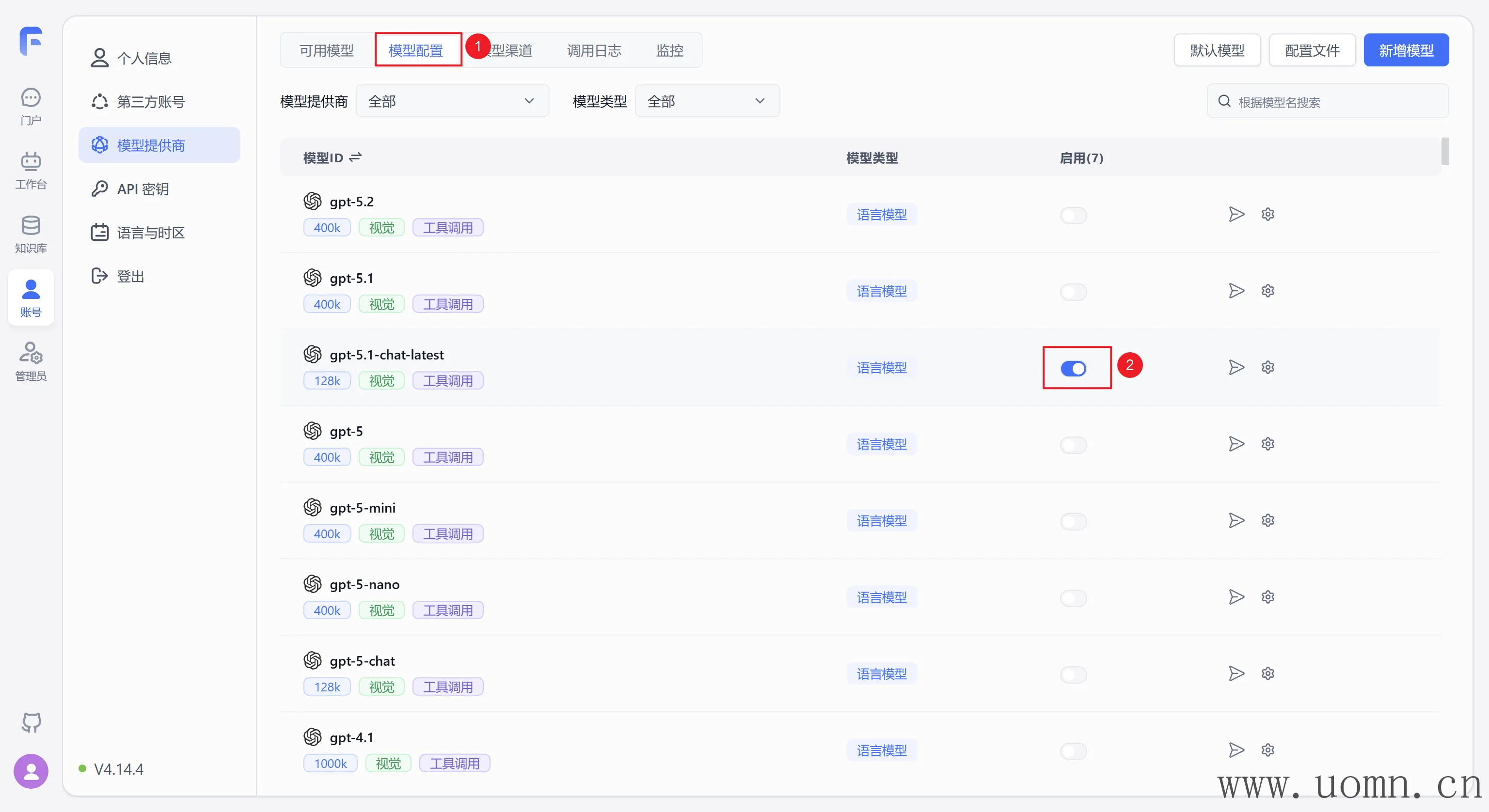
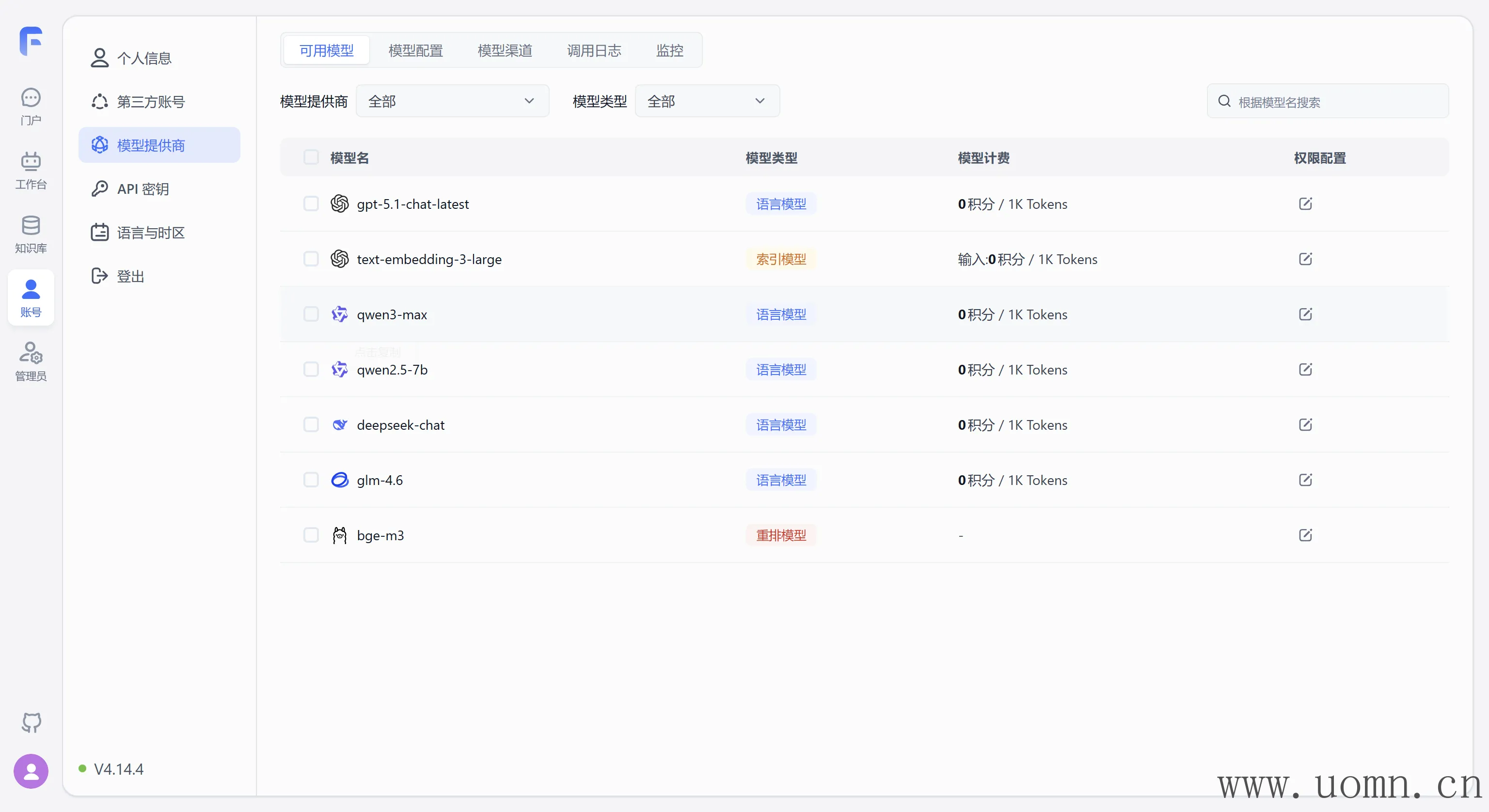
启用后在可用模型里能够看到
创建Agent
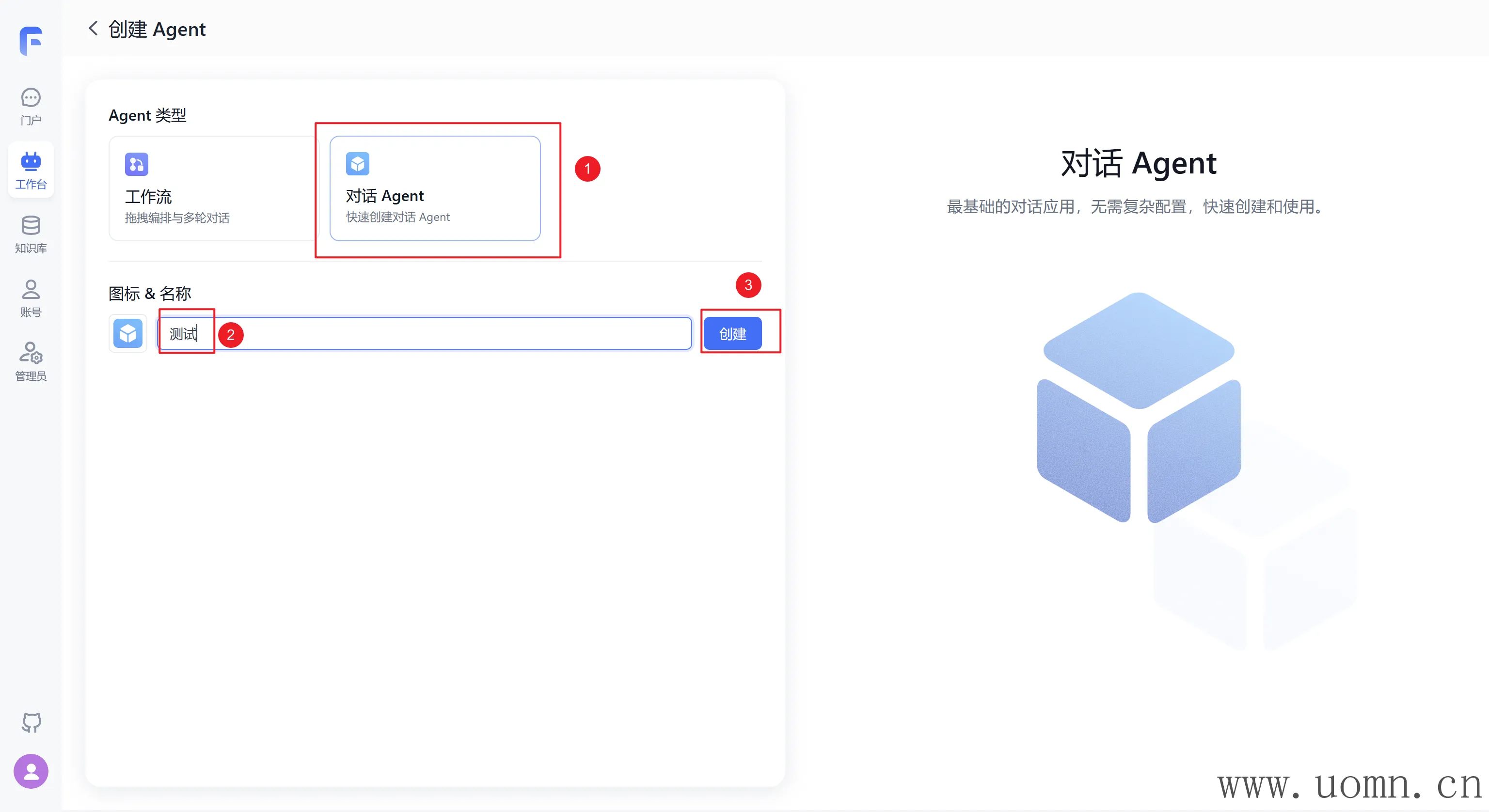
文本模型测试
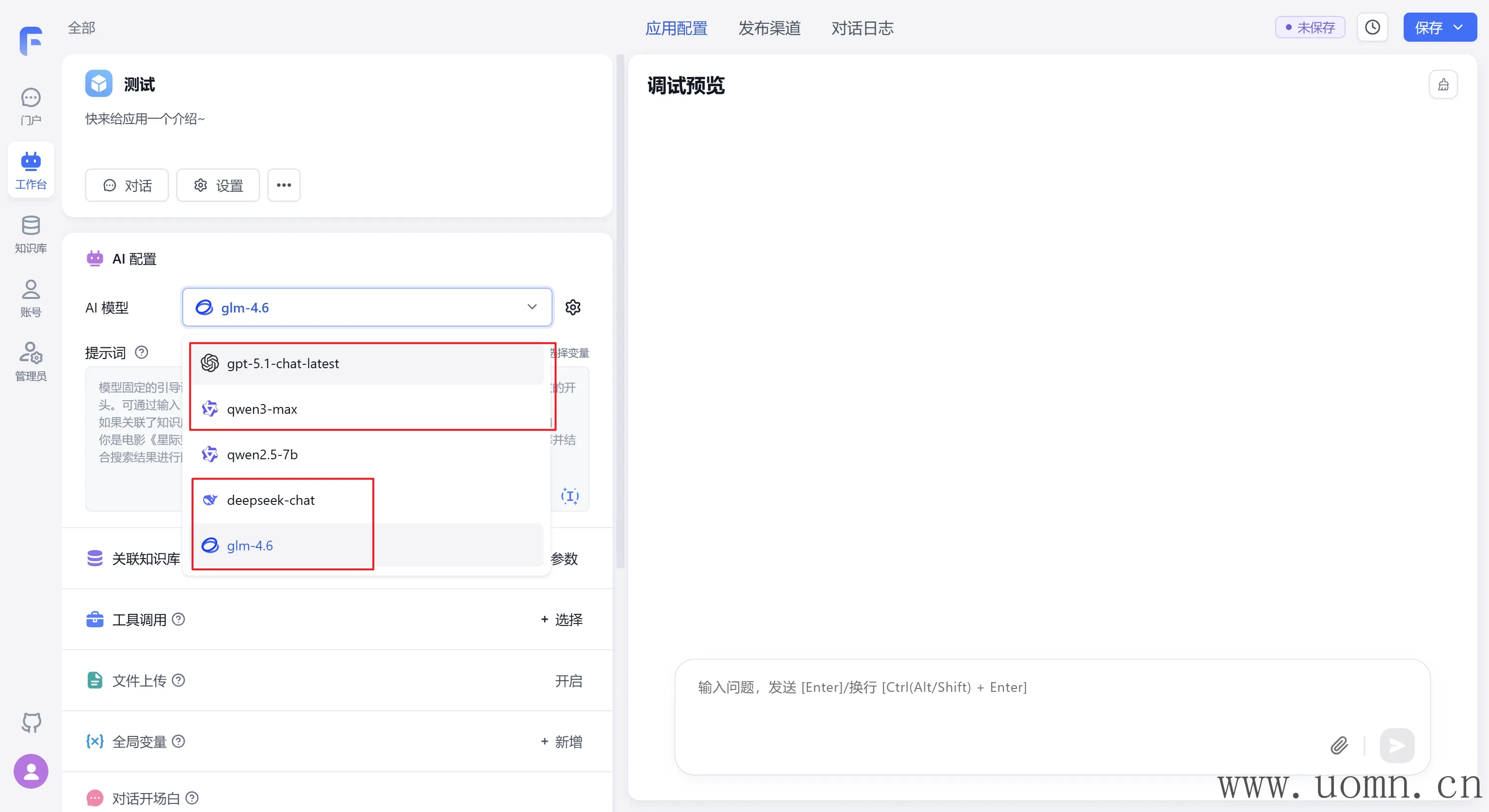
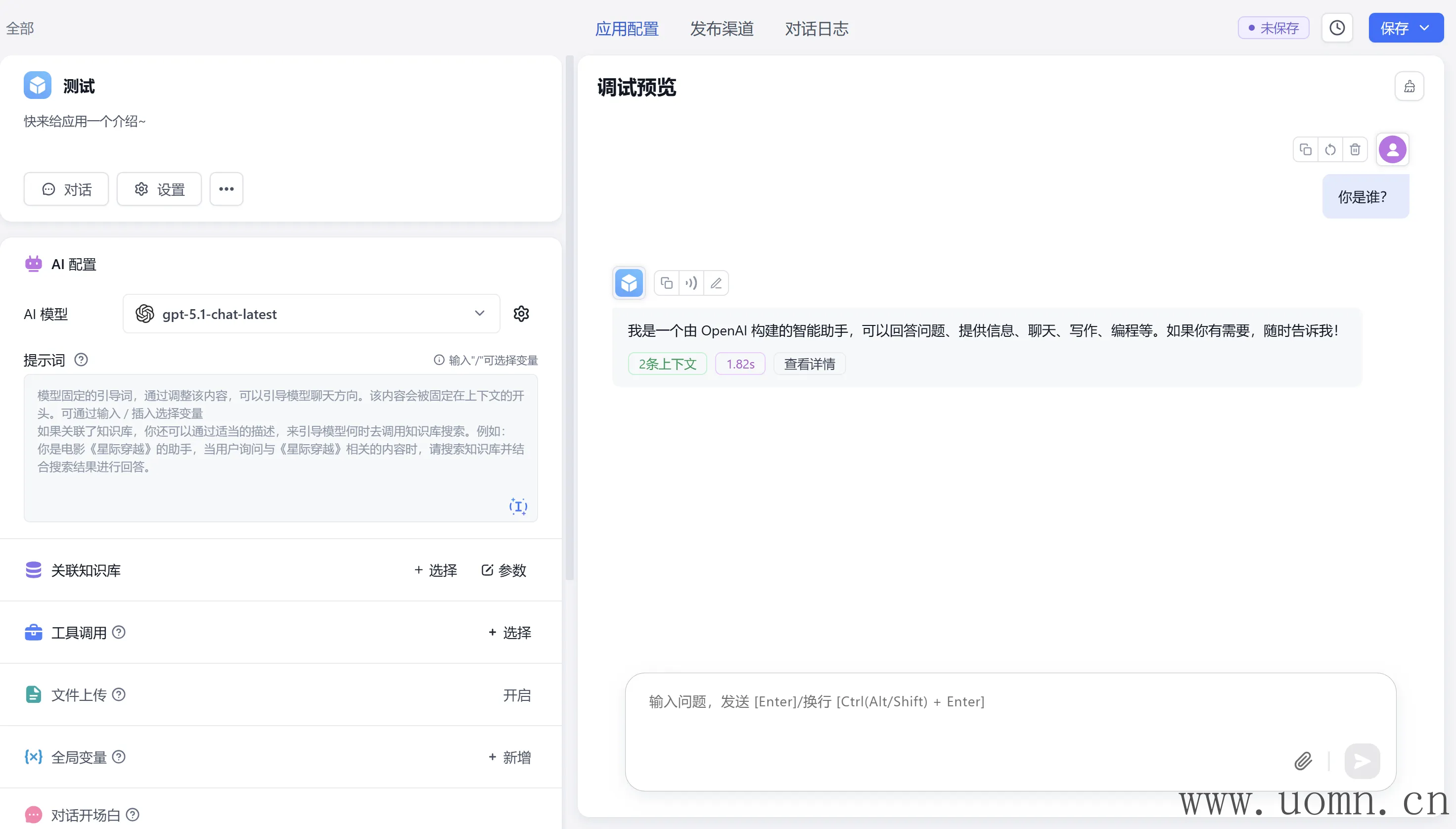
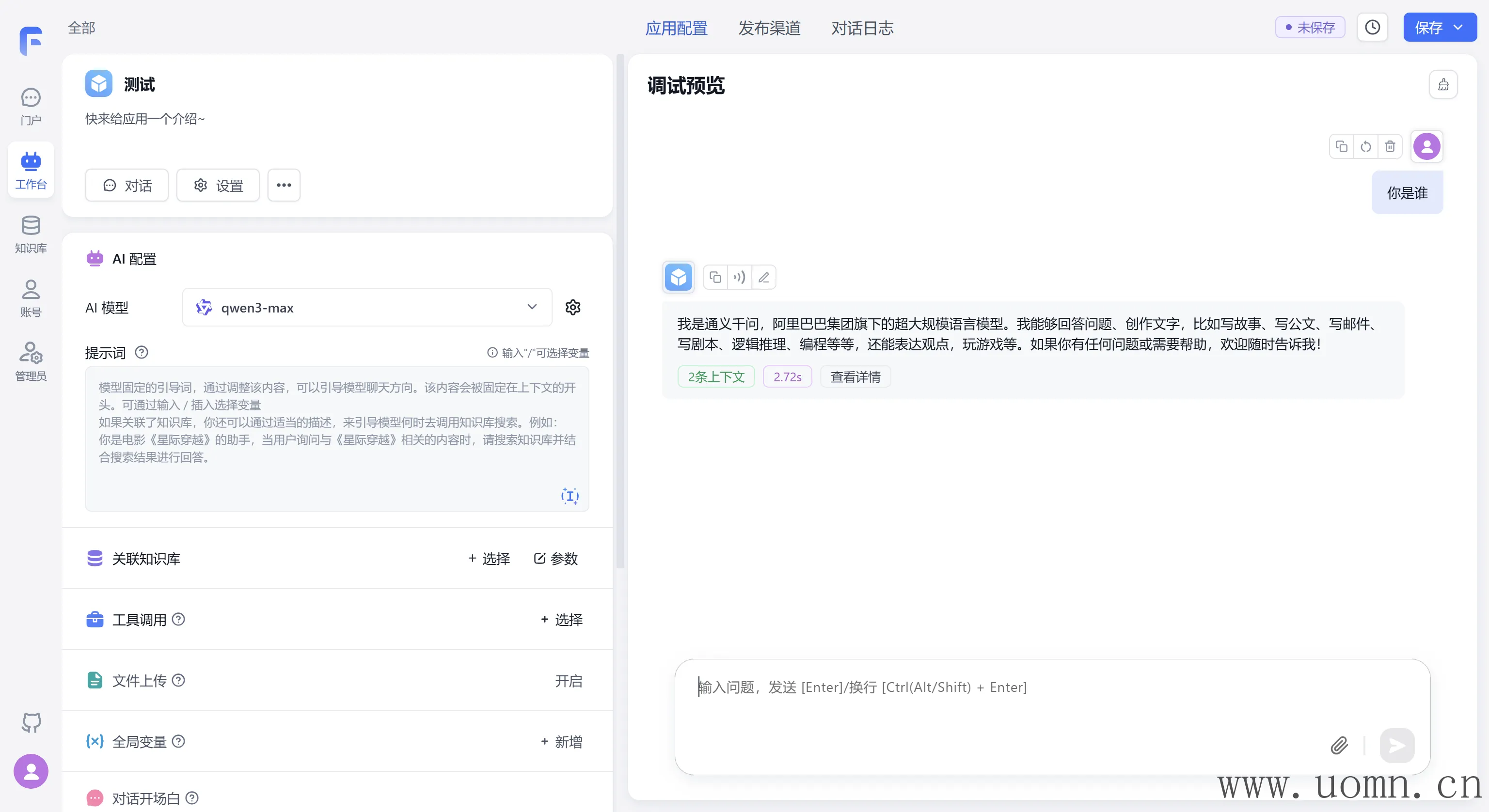
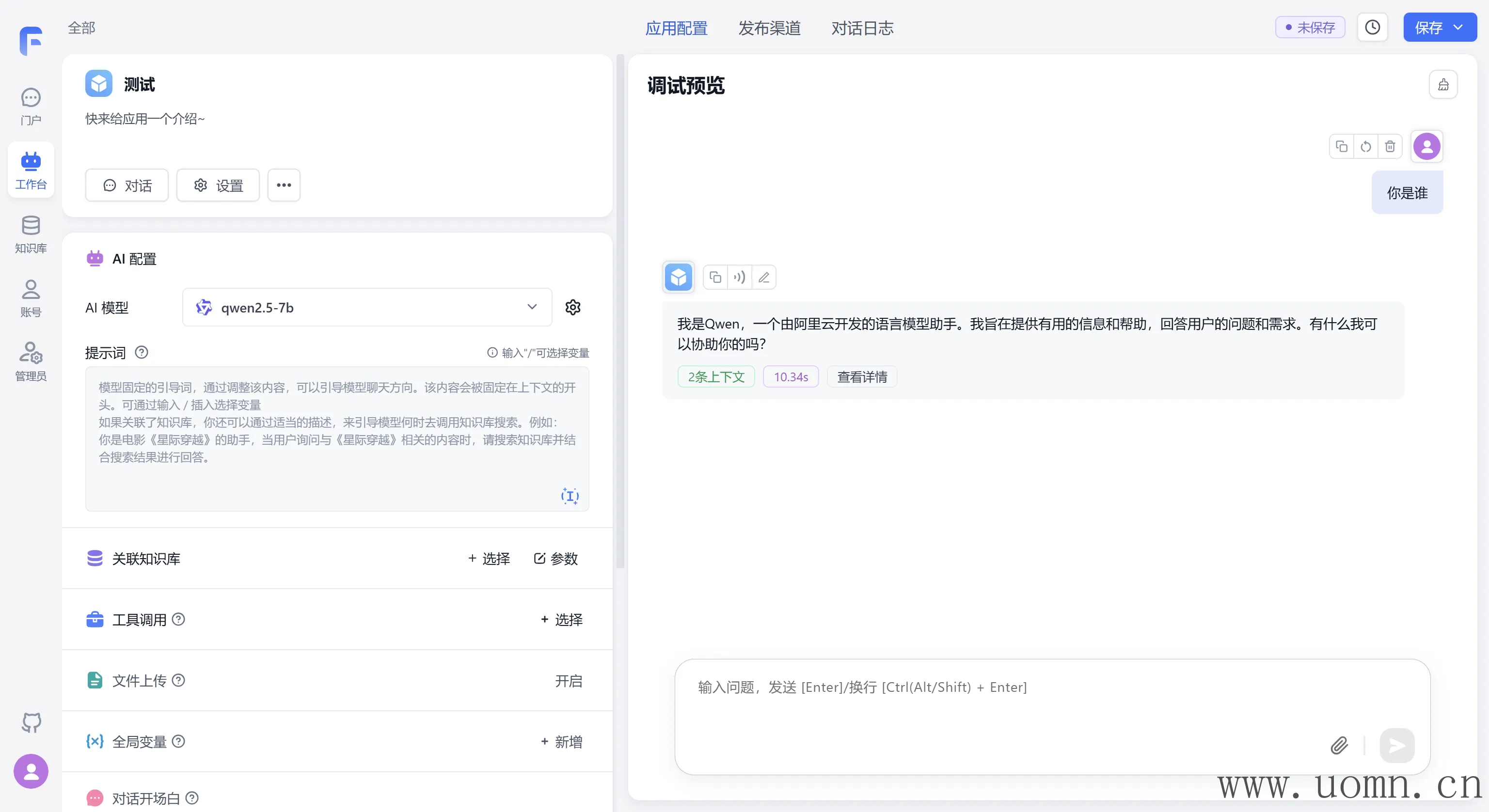
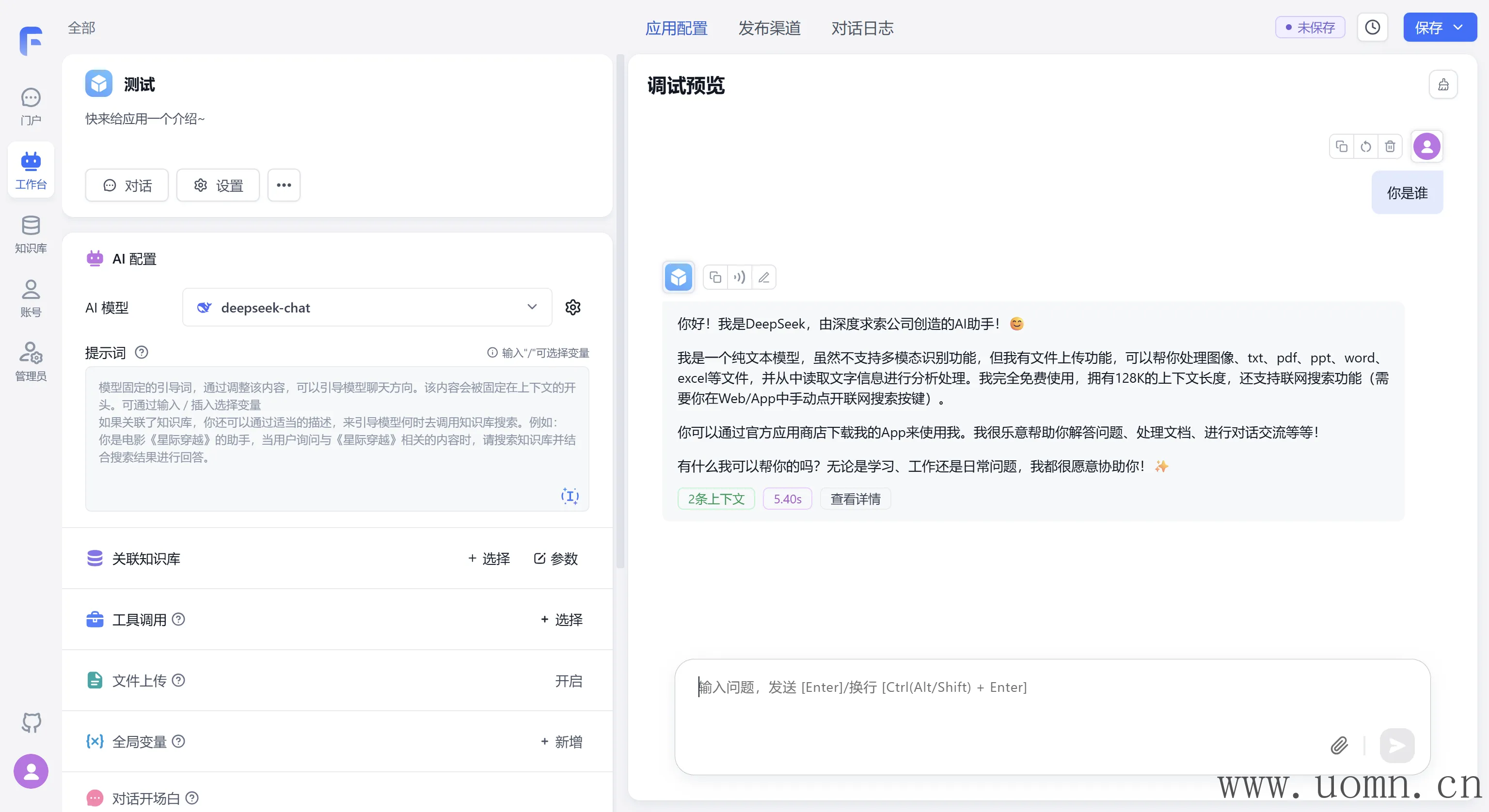
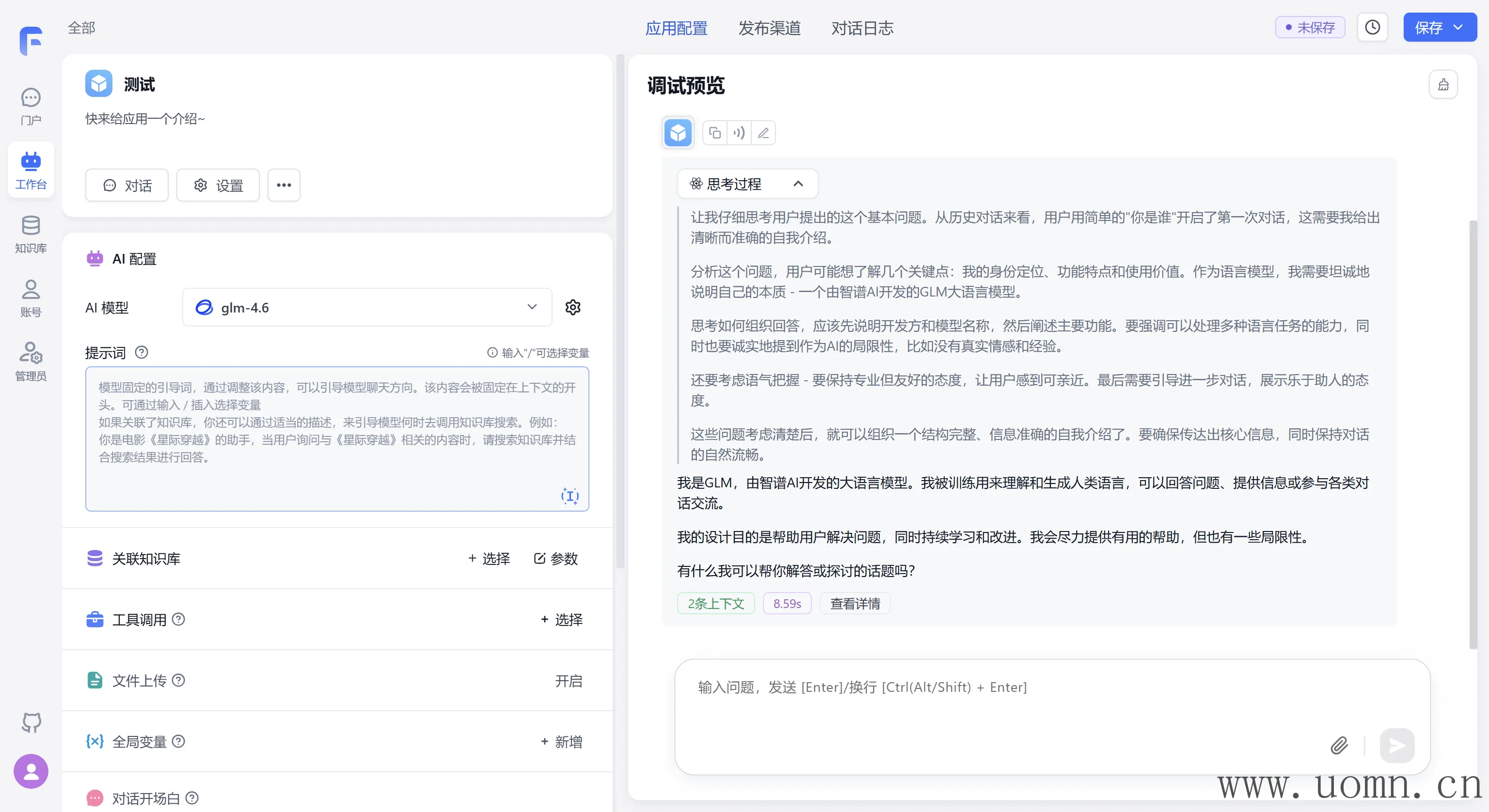
嵌入模型测试
嵌入模型需要创建两个知识库,一个用于测试在线模型,一个测试本地模型
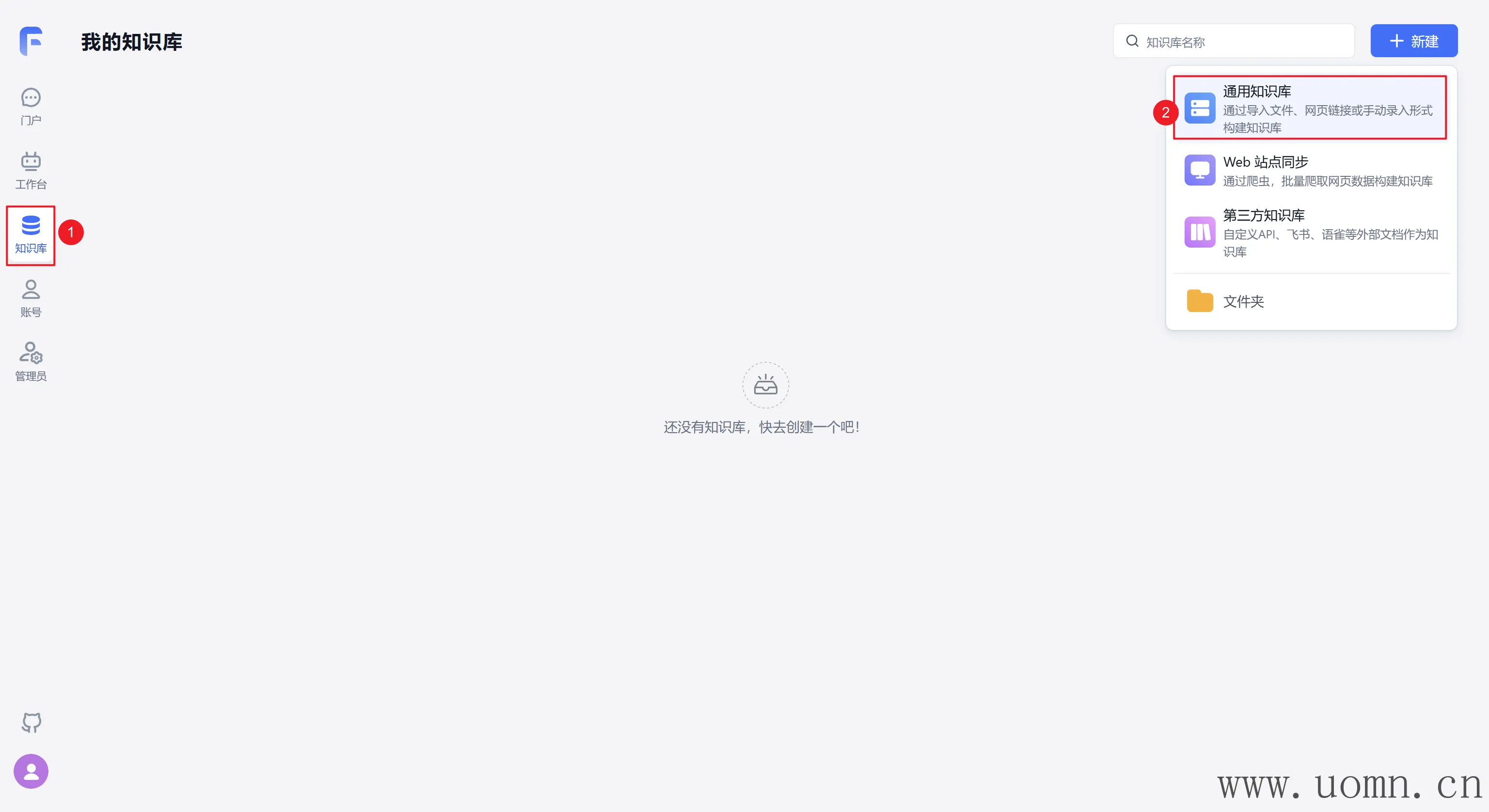
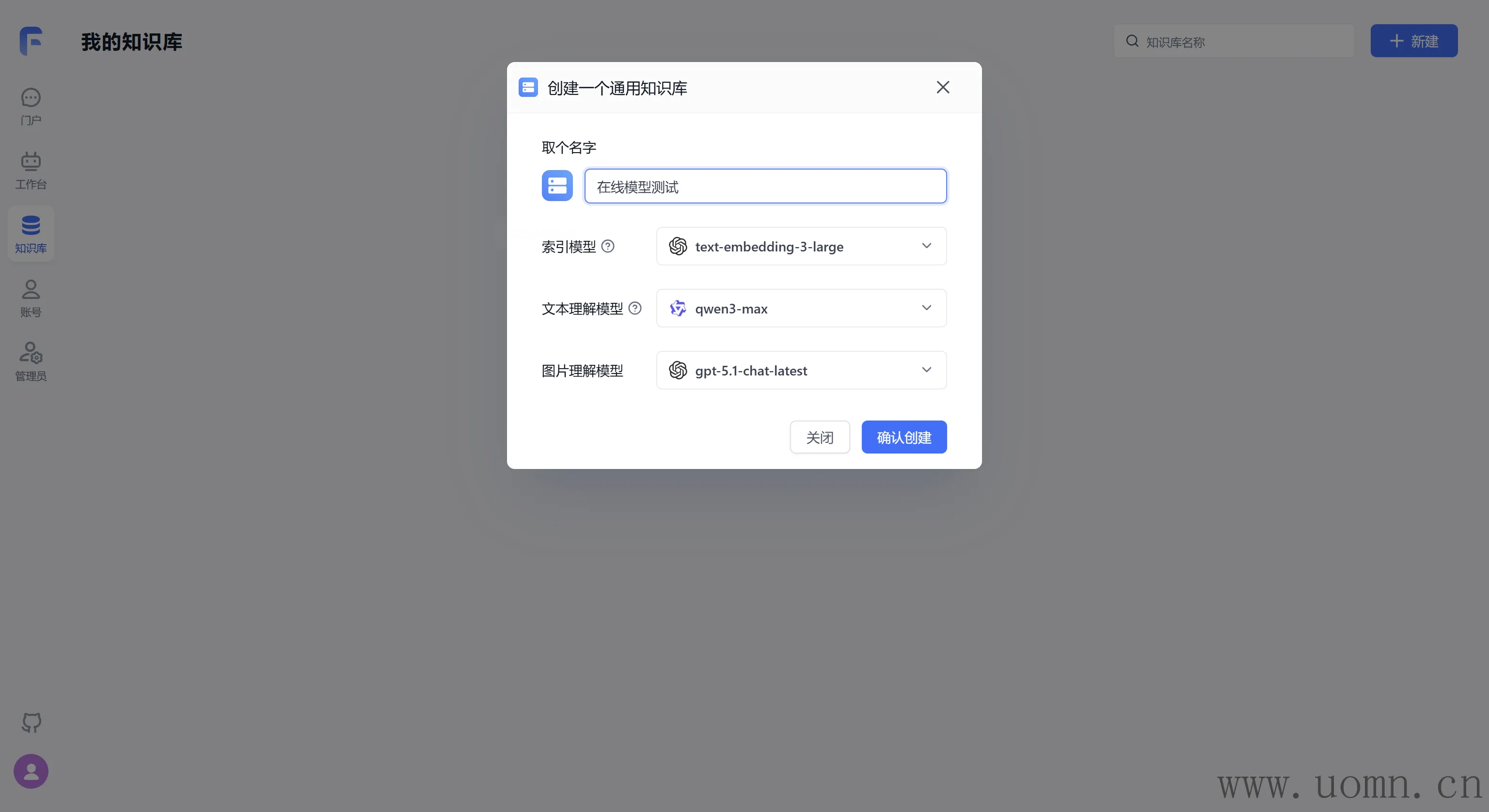
为了方便测试,这里随便搞几个问答对
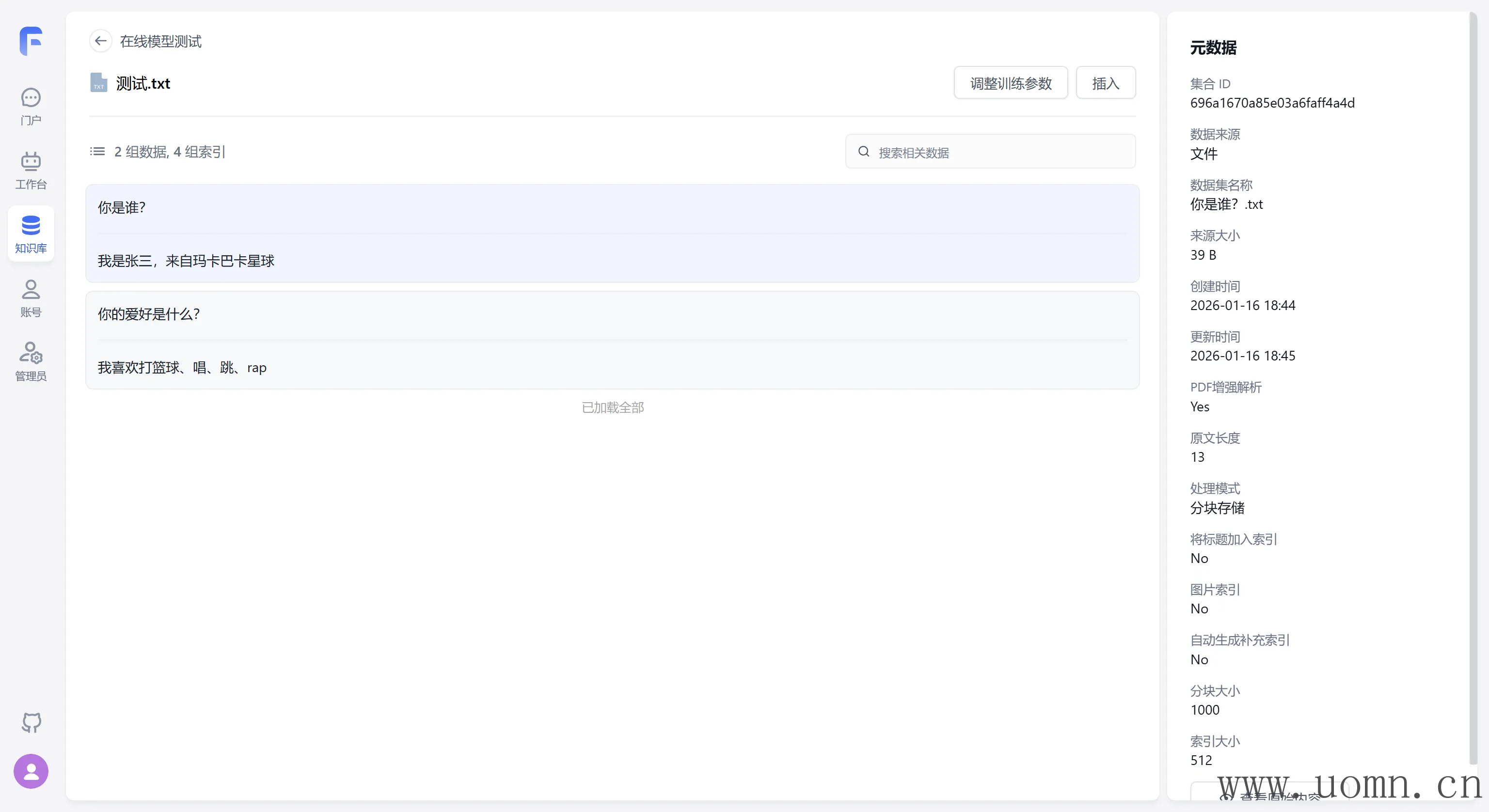
如果能够正常索引,则说明嵌入模型没问题
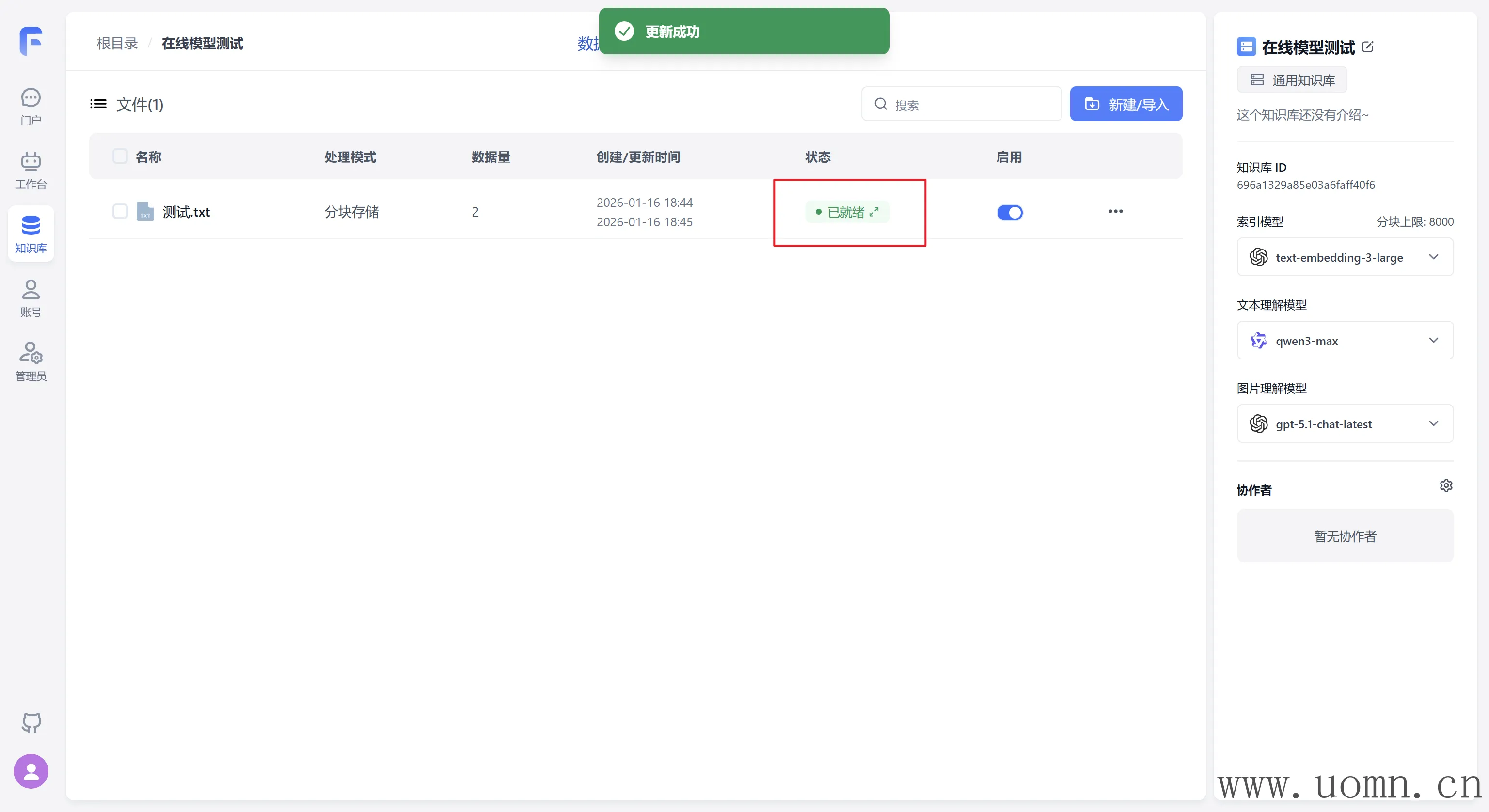
测试结果
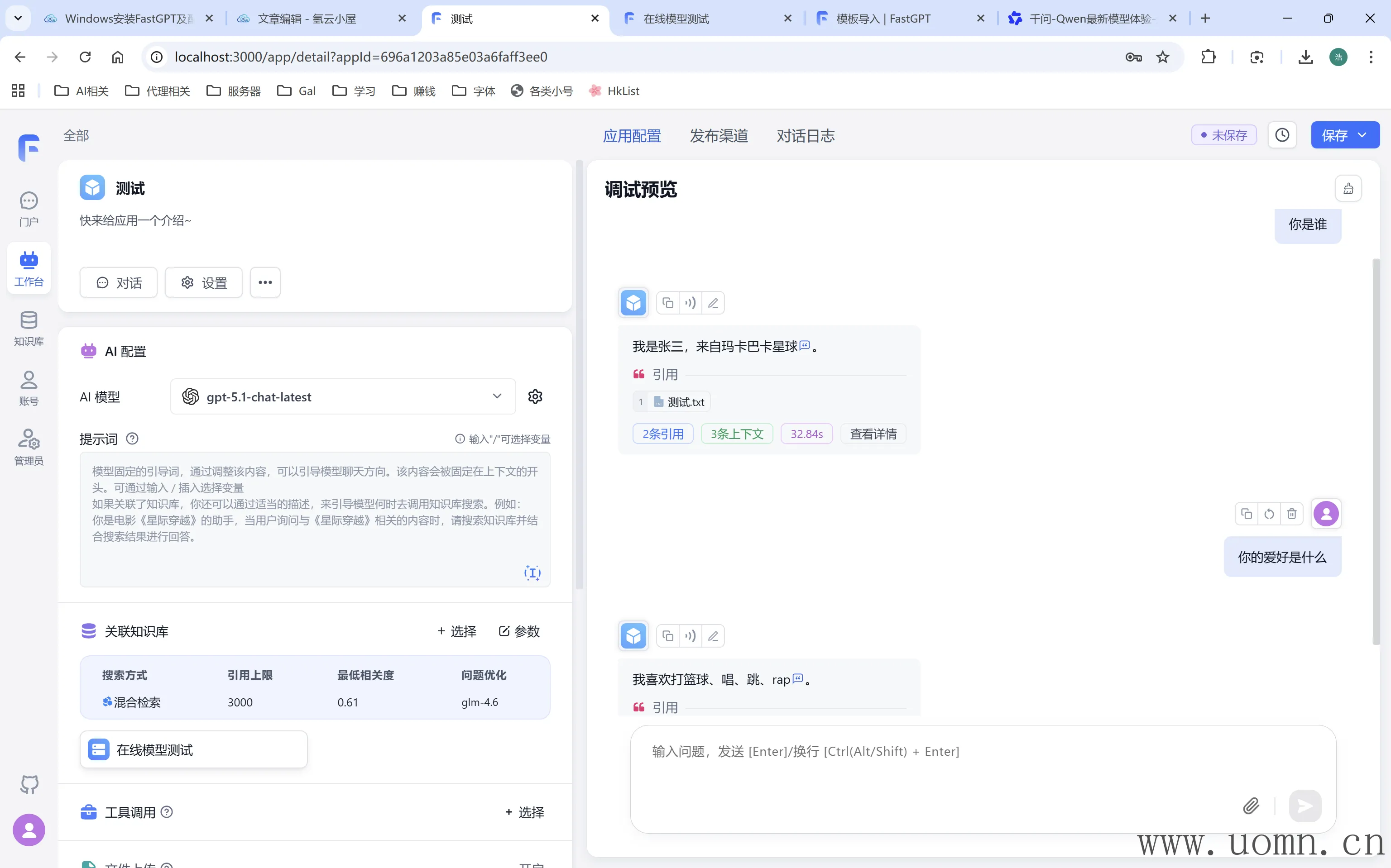
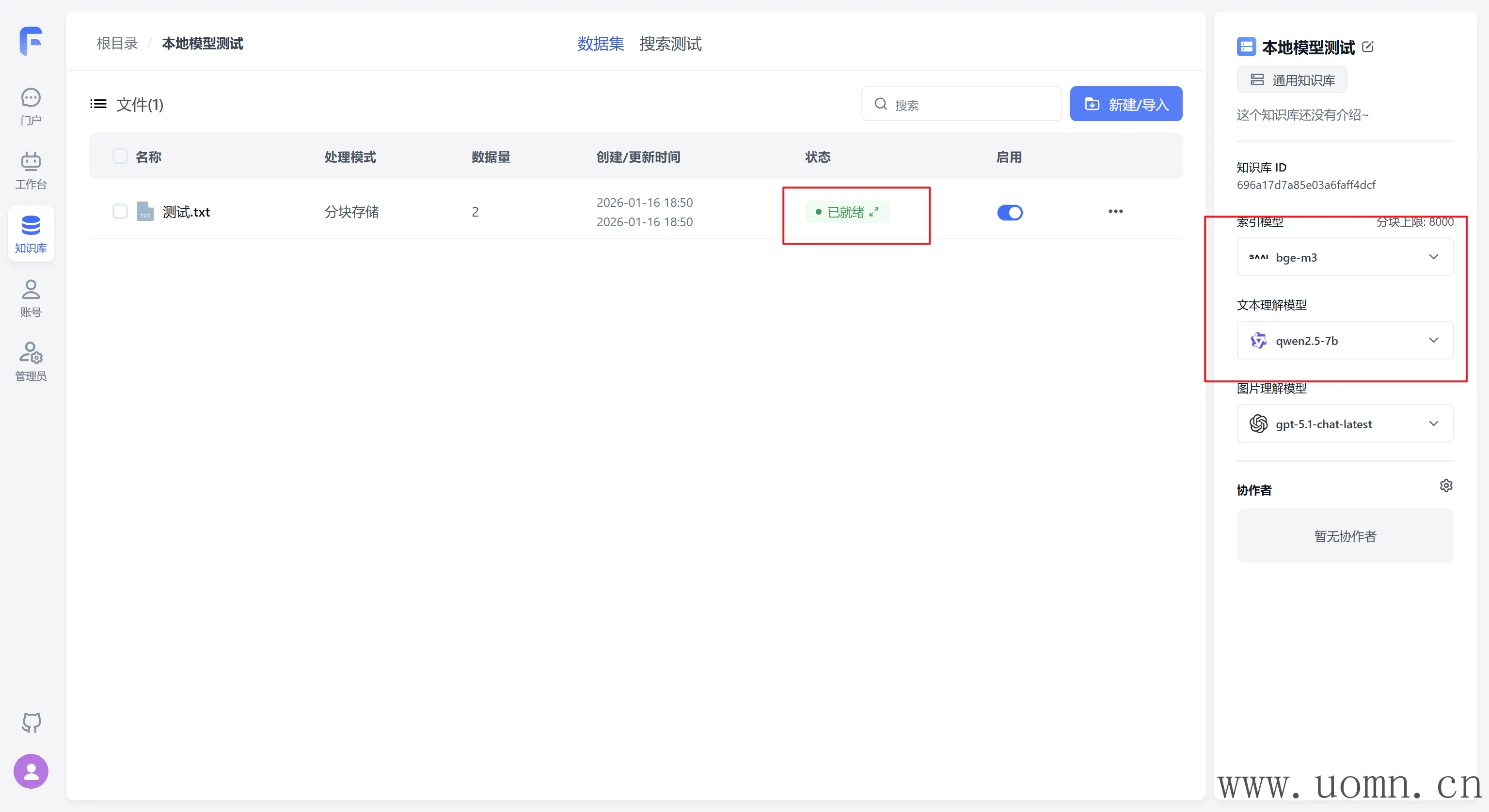
接下来测试本地模型
下图中的图片理解模型是在线模型,只有解析图片的时候才会调用,现在测试纯文本可以不用管
现在本地模型也没啥问题
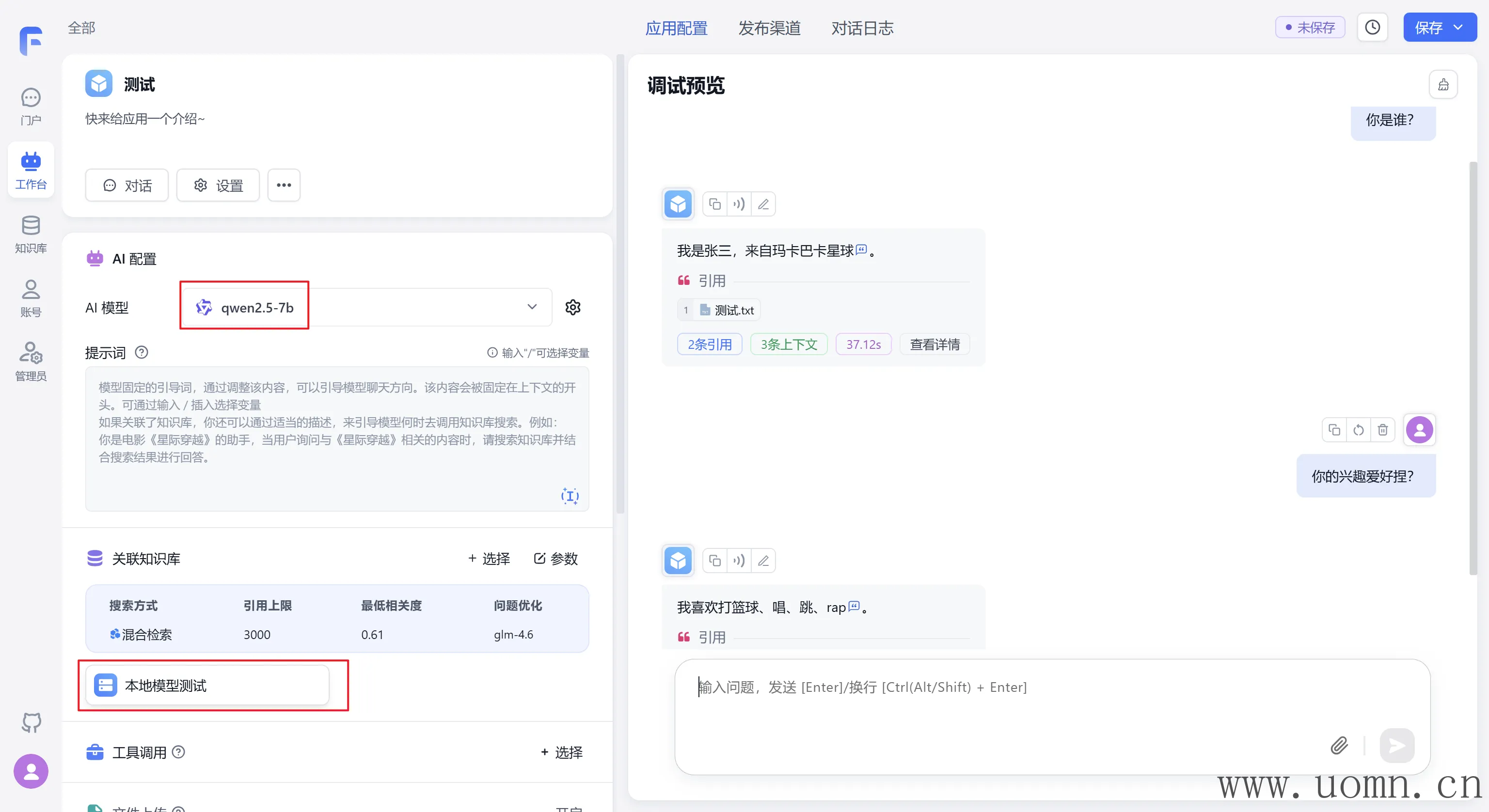
对话测试依旧没得问题
后记
那么至此FastGPT接入在线模型和本地模型的教程到此完结啦
有疑问可以在评论区留言哦!